해당 게시물은 한양대학교 컴퓨터소프트웨어학부 채동규 교수님 기계학습이론 온라인 강의를 듣고 정리한 자료입니다.
오류가 있다면 언제든 알려주세요!
Linear Regression이란 선형 회귀 분석으로 알려진 다른 데이터를 바탕으로 새로운 데이터를 예측하는 방법이다. 조금 더 쉽게 풀어서 말하자면 여러 요소들을 종합적으로 고려해서 하나의 target을 예측하는 것을 뜻한다.
Example: Predicting price of houses (Single input variable)

위의 예제에서 집크기는 independent(input) variable이고 그에 따른 집가격은 dependent(target) variable이다.
전자는 예측의 힌트가 되고 후자는 예측을 해야하는 값이다.
위처럼 15개의 데이터가 주어졌을 때 우리는 그 데이터를 그래프 상에 나타낼 수 있다.
그러면 오른쪽 위와 같은 점들이 찍히고 그 경향성을 고려해서 하나의 직선을 표현할 수 있는 것이다.
그 직선은 해당 데이터들을 가장 잘 표현할 수 있는 하나의 직선으로 $y=ax+b$로 표현된다.
그 후 이제 집크기, $X$ 값이 주어지면 해당 직선에 맞추어 집가격, $Y$값을 예측할 수 있다.
이것이 선형회귀 분석을 쉽게 설명한 예제이다.
Example: Price of old cars (multiple input variables)

또 다른 예제이다. 이번에는 input variable의 종류가 여러개이다.
차 가격은 여러개의 항목들이 고려되어 정해진다는 뜻이다.
What is Regression?
Regression(회귀)란 하나 이상의 입력값들과 출력값의 관계를 찾는 것이다.
Types of Regression
회귀의 종류에는 선형회귀(Linear regression), 다중회귀(multiple linear regression), 비선형회귀(Non-linear regression), 등 다양한 종류가 있다.
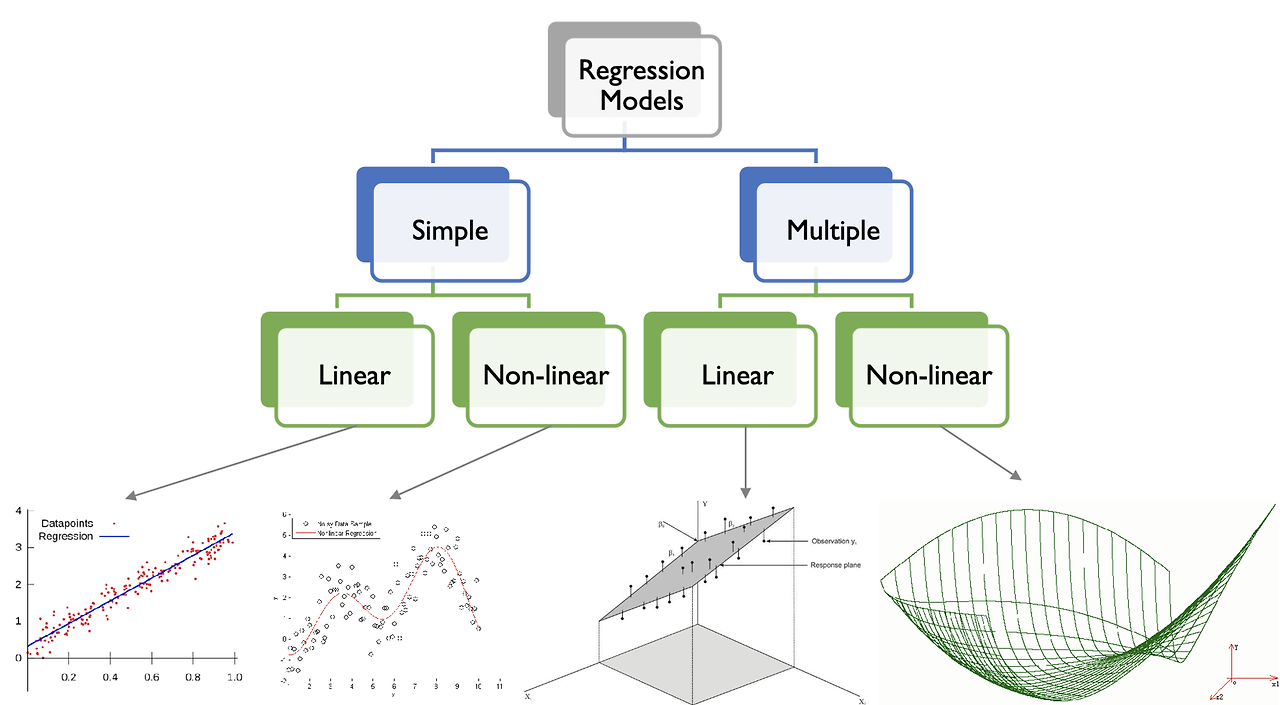
처음에 본 집 값에 대한 예측은 집크기라는 하나의 변수를 고려했고 직선으로 예측했으므로, Regression Models -> Simple -> Linear에 속한다.
두 번째로 본 차가격에 대한 예측은 여러개의 변수를 고려했고 직선으로 예측했으므로, Regression Models -> Multiple -> Linear에 속한다.
만약 하나의 값을 가지고 주식의 가격을 예측할 때는 곡선으로 예측하게 된다. 따라서 이는 simple non-linear regression이 된다.
2개 이상의 변수를 고려해서 직선으로 모델링하는 것이 가장 일반적인 회귀 방식이다.
1. Simple Linear Regression
· dependent variable $y$, single independent variable $x$를 포함한다. 다음과 같이 1차식의 형태로 표현된다.
$y = w_{0} + w_{1}x$
여기서 $w_{0}$($y$ 절편, input data와 관계없이 일반적인 현상), $w_{1}$(기울기)는 model parameter로 $w_{0}$과 $w_{1}$를 예측해야한다.
· $w_{0}$와 $w_{1}$는 학습 데이터 학습을 통해 결정되어야 한다.
따라서 학습은 우리에게 주어진 데이터 $x, y$를 가장 잘 설명할 수 있는 model parameter를 찾는 것이다. 최적화와 같은 의미이다.
2. Multiple Linear Regression
· 2개 이상의 independent/input variable을 가지고 있다. 입력값은 벡터 형태로 보통 표현한다.
$X = <x_{1}, x_{2}, ..., x_{n}>$: input variable
$y$: dependent/output/target variable
· 학습 데이터는 당연히 $(X_{1}, y_{1}), (X_{2}, y_{2}), ..., (X_{|D|}, y_{|D|})$ 형태로 구성된다.
· 2개의 input variable이 주어진다고 하면 학습을 통해 $y = w_{0} + w_{1}x_{1} + w_{2}x_{2}$ 형태로 모델이 표현될 것이다.
ex) d개의 input variable $x_{1}, x_{2}, ..., x_{d}$가 주어지고 target variable $Y$를 모델링하면 다음과 같이 표현된다.
$$\hat{y} = \hat{\beta_{0}} + \hat{\beta_{1}}x_{1} + \hat{\beta_{2}}x_{2} ... + \hat{\beta_{d}}x_{d}$$
학습은 여기서 계수 $\hat{\beta} = [\hat{\beta_{0}}, \hat{\beta_{1}}, ..., \hat{\beta_{d}}]$를 찾아내는 것이다.
계수 벡터 $\hat{\beta}$는 d+1차원이다.
Which model is the best?
어떻게 최적인 $\hat{\beta}$를 구할 수 있을까.
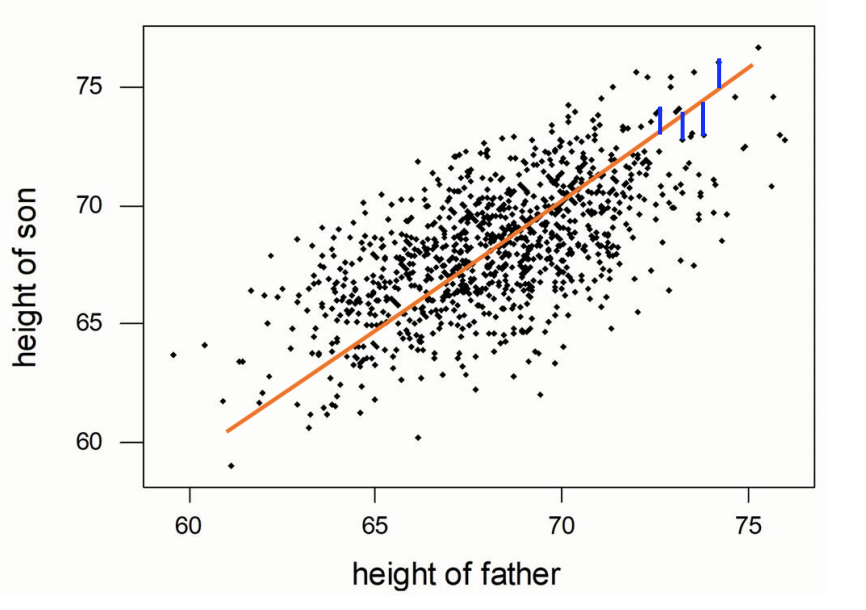
이렇게 임의의 모델이 있을 때 파란색 선과 같이 실제 데이터와 예측 값의 차이를 error라고 한다. 모든 데이터들과 예측값의 차이를 구한 다음 그 합이 최소일 때의 $\hat{\beta}$값을 최적값이라고 한다.
Model Training
1. cost(loss, error) function E를 정의한다.
이는 실제값과 모델의 예측값의 차이이다.
2. 최적화를 한다.
error function E를 최소화시키는 최적의 $\hat{\beta}$값을 찾는다.
$E = \frac{1}{2}\sum\limits_{i=1}^n(y_{i}- \hat{y_{i}})^2$
$\hat{\beta} = \underset{\beta}{\operatorname{argmin}}\frac{1}{2}\sum\limits_{i=1}^n(y_{i}- \hat{y_{i}})^2$
$= \frac{1}{2}(y_{i}-(\hat{\beta_{0}} + \hat{\beta_{1}}x_{i1} + \hat{\beta_{2}}x_{i2} ... + \hat{\beta_{d}}x_{id})^2)$
$\sum($실체값$ - ($우리 모델의 예측값$))^2$ 을 가장 minimize하는 $\beta$를 찾자.
How to solve the optimization problem?
1. Cost function E가 단순할 때
input variable이 하나인 simple linear regression일 때는 제곱 형태로 손실함수가 나오기 때문에 $\beta$에 대한 미분으로 쉽게 optimal parameters를 구할 수 있다.
$$\frac{\partial{E}}{\partial{\beta}} = 0$$
2. Cost function E가 복잡할 때
multiple model parameters를 가질 때는 미분만으로는 값을 도출할 수 없다. 미분값이 0이 되는 부분이 굉장히 많기 때문이다. 이때는 다른 방법을 써야된다. 해당 포스터말고 추후에 다룰 예정이다.
해당 포스터에는 1번 경우인 Cost function E가 단순할 경우를 다루도록 하겠다.
1. Prepare variables and model parameters
먼저 우리는 행렬을 통해 계산할 예정이다.
$X: n * (d + 1) matrix, y: n * 1 vector, \hat{\beta}: (d + 1) * 1 vector$
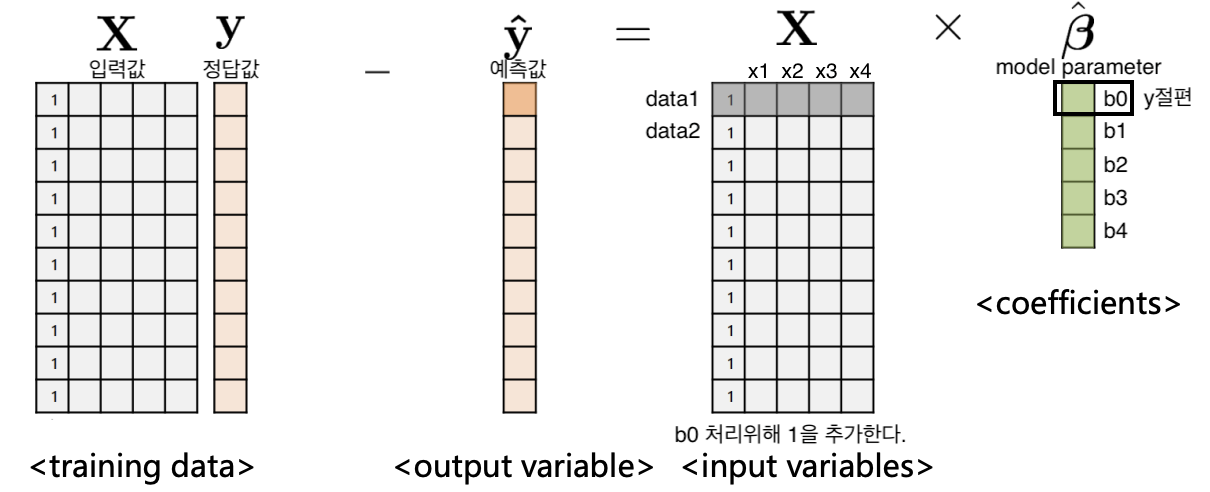
$$\hat{y_1} = \hat{\beta_{0}} + \hat{\beta_{1}}x_{1} + \hat{\beta_{2}}x_{2} ... + \hat{\beta_{4}}x_{4}$$
이는 첫번째 data에 대한 model parameter를 이용한 예측값이다.
2. Defining loss function
Loss function을 미분해서 최적의 $\beta$를 찾아보자.
가장 기본적인 선형대수 공식을 써서 계산한다.
· $(ABC)^T = C^TB^TA^T$
· $a^T = a$

이를 통해서 data $X$를 가장 잘 설명해줄 수 있는 model parameter $\beta$를 찾을 수 있다.
미분할 때 다음과 같은 네 가지 공식은 기억하고 있는 것이 좋다.
$$\frac{\partial (AX)}{\partial X} = A^{T}$$
$$\frac{\partial (X^{T}A)}{\partial X} = A$$
$$\frac{\partial (X^{T}X)}{\partial X} = 2X$$
$$\frac{\partial (X^{T}AX)}{\partial X}=AX+A^{T}X$$
따라서 $\hat{\beta} = (X^TX)^{-1}X^Ty$가 loss function을 최소로 하는 model parameter로 도출된다.
'3-2 > 기계학습이론' 카테고리의 다른 글
| [기계학습] Gradient Descent(경사하강법)_2 (0) | 2024.10.17 |
|---|---|
| [기계학습] Gradient Descent(경사하강법)_1 (6) | 2024.10.13 |
| [기계학습] Linear Regression_과적합 해결하기 (2) | 2024.10.13 |