* 12.18 업데이트
해당 게시물은 한양대학교 컴퓨터소프트웨어학부 김상욱 교수님 데이터베이스시스템 온라인 강의를 듣고 정리한 자료입니다.
오류가 있다면 언제든 알려주세요!
● 해당 강의의 목표
1. Relation Schema를 design하기 위한 guideline과 functional dependency의 개념을 배운다.
▪ database schema가 잘 되었는지 확인하는 기준
▪ 잘된 db schema를 design하는 방법
▪ functional dependency의 개념
◆ Informal Design Guidelines for Relation Schema
◆ Relational database를 design한다는 것은?
▪ 주어진 application을 위한 좋은 table schema들을 define하는 과정이다.
▪ database는 몇 개의 table로 구성이 될 것인지, 각각의 table에는 어떤 attribute이 포함될 것인지 등을 decide하는 과정이다.
◆ table schema를 보고 good인지 아닌지 informal 결정하는 기준
▪ attribute의 의미적인 측면
▪ tuple 내에 중복된 정보들이 나타나는가
▪ tuple 내에 NULL 값이 있는가
▪ 가짜 tuple들이 생길 여지가 있는가
◆ Formal criteria
▪ Normalization (이후에 배운다.)
◆ Semantics of Attributes in Relations
◆ table schema를 결정할 때
▪ 하나의 table에 속하는 모든 attribute는 real-world에서 상호 관련된 의미를 가져야한다.
▪ Ex) STUDENT (name, age, gender, address) 하나의 real-world에서 특정한 한 학생에 대한 정보라는 점에서 모두 연관되어 있다.

◆ Guideline 1
◆ table에 속한 각각의 tuple은 real-world에서 존재하는 하나의 entity instance이거나 하나의 relationship instance이어야한다.
◆ 여러 attribute을 combine하면 안 된다. 2개 이상의 entity type에 속하는 attribute를 combine해서 하나의 table에 넣거나 2개 이상의 relationship type에 속하는 그러한 attribute들을 묶어서 하나의 table에 넣는 것을 피해라.

위의 예시에서는 Employee와 Department에 대한 정보가 섞여서 하나의 table 안에 들어와 있다. 일단 화살표는 무시하자.
이는 guideline1을 위반하였다.
1. 2가지 이상의 entity type에 속하는 attribute이 하나의 table에 섞여있다.
◆ Redundant Information
redundant하다는 것은 정보가 중복되어 있다는 뜻이다.
◆ storage space를 줄여야한다.
▪ table schema design에서 중요한 goal이다.
▪ redundant information을 제거해야한다.



EMP_DEPT는 Dnumber, Dname과 Dmgr_ssn이 여러 번 중복되어 있다. 따로 2개의 table로 이루어졌을 때는 이와같은 중복이 발생하지 않았다. 따라서 2개의 entity에 대한 정보를 합쳐놓는 것은 redundant information 측면에서도 좋지 않다. 1:N의 관계에서 그 것을 같은 table안에 넣으면 중복 문제가 발생한다.

해당 경우에도 redundant information이 발생한다. 서로 다른 entity에 대한 정보를 하나의 table에 섞었기 때문에 발생한다.
◆ Update Anomalies (update 이상)
◆ 예상했던 방향과 다르게 update가 동작하는 것을 말한다.
▪ Insertion
▪ Deletion
▪ Modification
◆ Insertion anomalies
▪ EMP_DEPT 테이블에 department를 하나 만들어서 집어넣고 싶은데 department 정보만 가지고는 해당 table에 집어넣을 수 없다. employee 테이블도 필요하다.
▪ table design이 잘못되었기 때문에 발생하는 것이다. DEPARTMENT와 EMPLOYEE를 분리해서 가지고 있어야한다.
◆ Deletion anomalies
▪ EMP_DEPT table에서 department X에 Y라는 employee 한 사람만 남았다고 하자. 이런 상황에서 department만 남겨두고 employee만 지우고 싶을 때 문제가 발생한다. 그 employee를 지우면 마지막 tuple의 key가 설정되지 않는다. 따라서 Y는 삭제되지 못한다.
▪ DEPARTMENT와 EMPLOYEE를 분리해서 가지고 있어야한다.
◆ Modification anomalies
▪ EMP_DEPT에서 department X의 manager를 바꾸고 싶다고 하자. 그러면 해당되는 department에서 일하는 모든 employee에 대해서 manager 정보를 바꾸어주어야한다. 이를 제대로 해주지 않으면 데이터의 일관성이 깨진다.
▪ DEPARTMENT와 EMPLOYEE를 분리해서 가지고 있어야한다.
◆ Guideline 2
◆ Relation Schema를 디자인하는데에 있어서 이러한 update anomalies가 생기지 않도록 디자인해야한다.
◆ 만약 anomalies가 존재하는 것을 안다면, 1. 어떠한 anomaly인지 알고, 2. 프로그램이 어떻게 동작해야하는지 알아보고 고쳐야한다.
◆ NULL Values in Tuples
◆ NULL의 의미
▪ Unknown value / Unavailable
▪ not applicable ex) super_ssn이 NULL이면 회장님이다.
◆ NULL 값의 문제점
▪ 저장 공간의 낭비
▪ 모호한 의미
▪ aggregate function을 적용하는데에 어려움이 있다. ex) 연봉 평균을 구하고 싶은데 null이 너무 많으면 유의미한 정보를 얻기 어렵다.
◆ Guideline 3
◆ base table에 null 값이 자주 나오도록 하면 안된다. ex) 1 : 1 relationship 일 때 primary key를 어느 쪽에 가져와도 되지만 보통 total에 가져온다.
◆ NULL value를 완전히 피할 수 없을 때
1. 가급적이면 tuple의 대부분의 경우가 null이 되는 상황을 피하자.
2. Table을 분리해서 Null값이 아닌 value들만 가지는 tuple들만 가지는 새로운 tuple로 만들어준다.
◆ Example
▪ 전체 employee의 10%가 자기자신의 개별 office를 갖는다고 가정하자.
▪ Method 1
- EMPLOYEE table에 Office_number라는 attribute를 넣으면 90%의 tuple은 NULL값을 가진다. 이는 공간적인 낭비가 심하다.
▪ Method 2
- EMP_OFFICES (Essn, Office_number) table을 하나 만든다.
- EMPL_OFFICES 테이블은 오직 office를 가지고 있는 emplyoee와 관련된 tuple만 들어간다.
◆ Spurious Tuples
◆ NATURAL JOIN 했을 때 invalid information, 즉 진짜 database 안에 있어서는 안 될 tuple이 생기는 것이다.
▪ 이를 가짜 tuple이라고 하고 database를 디자인할 때 잘못해서 생기는 것이다.
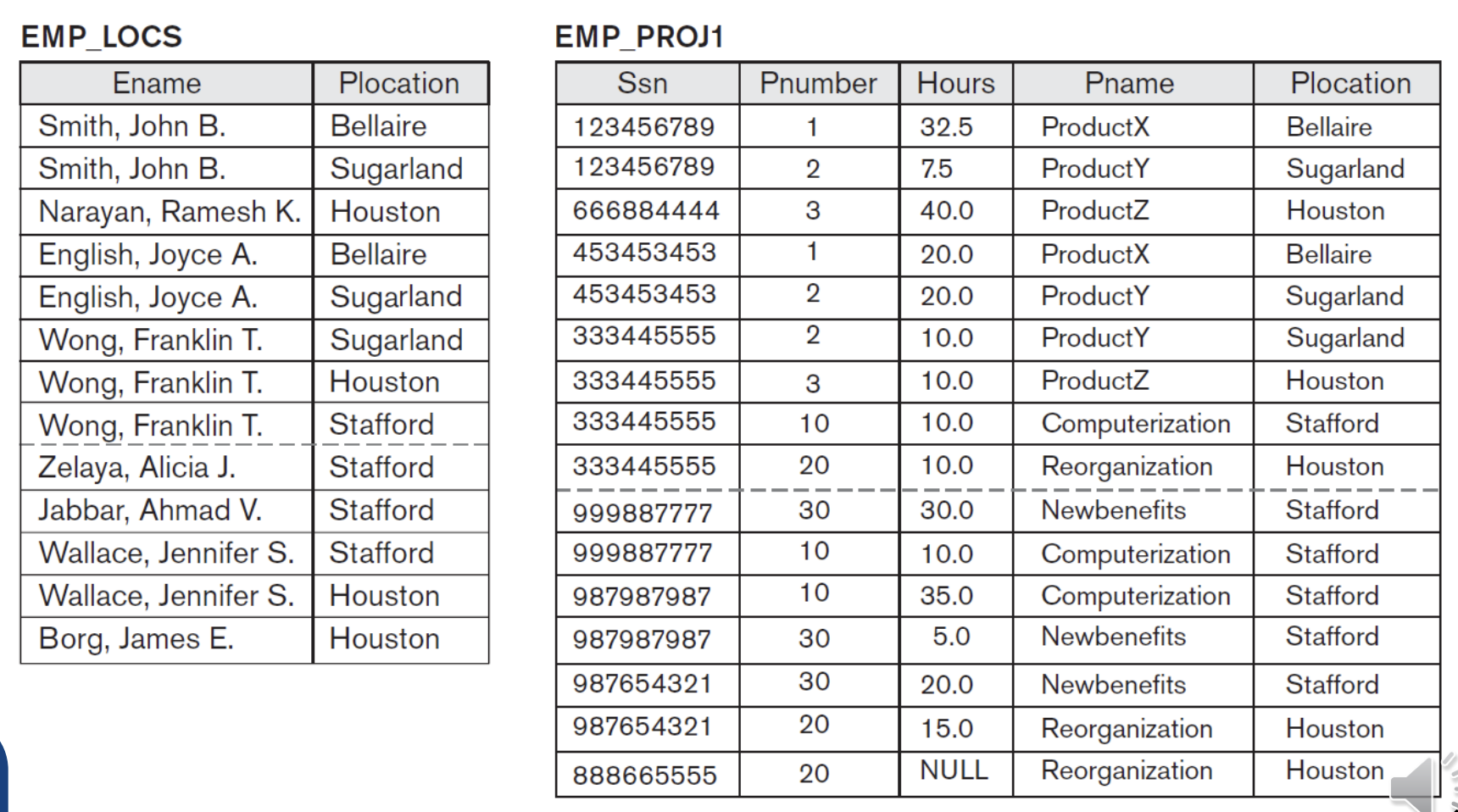
만약 위 두 개의 table을 join할 때 NATURAL JOIN을 하면 Plocation이 common attribute이기 때문에 이를 기준으로 join하게 된다. 하지만 보통 join은 PK와 FK 간에 하는데 양 table에서 Plocation이 PK, FK 모두 아니다. 따라서 이를 join하게 되면 가짜 tuple들이 만들어지게 된다.

*에 해당되는 tuple들은 원래 table에 존재하지 않았던 것이다.
◆ Guideline 4
◆ Relation을 만들어 낼 때 join attribute으로 FK, PK가 combination되지 않으면 안 된다. 따라서 design할 때 FK와 PK가 combination되도록 나누어야한다.
◆ Functional Dependencies
◆ Concepts
▪ relational schema를 분석할 수 있는 formal한 도구이다.
▪ key와 함께 normal form인지 여부를 판단한다.
◆ Format
▪ X -> Y , X, Y: relation schema R에 들어가는 attribute들의 집합
▪ X라는 attribute이 Y라는 attribute를 functionally determine한다. 또는, X의 value가 Y의 value를 함수적으로 결정한다.
▪ Y의 value가 X의 value에 함수적으로 dependent된다.
함수는 어떤 것과 다른 어떤 것의 mapping인데 어떤 것에서 같은 값은 가지면 다른 어떤 것에서도 값은 값을 가지게 되는 것을 function이라고 정의한다. X가 결정되면 Y값이 자동으로 결정되는 것, 이것을 함수적 종속성이라고 한다.
◆ Meanings
▪ X가 Y를 함수적으로 결정한다의 의미는 무엇일까?
주어진 relation에 2개의 tuple $t_1$과 $t_2$가 있다. 이때 $t_1[X]$ = $t_2[X]$ 면 $t_1[Y]$ = $t_2[Y]$ 이어야 한다. 2개의 tuple에 X라는 attribute 값이 같다면 Y값도 항상 같아야 한다. 이 것이 X의 value가 Y의 value를 함수적으로 결정한다는 의미이다.
- 만약에 tuple들이 X라는 attribute에 대해서 같은 값을 갖는다면 Y라는 attribute에 대해서도 같은 값을 가지게 된다.
- 즉, X라는 attribute 값이 Y라는 attribute값을 unique하게 결정한다.
▪ real-world application에서는 어떻게 나타날까?
- Department -> School: 학생이라는 table에서 department attribute은 school을 함수적으로 결정한다. 임의의 두 학생이 있을 때 두 학생이 같은 학과에 있는 학생이라면 두 학생의 학교는 같아야한다. 두 학생이 컴소학생이라면 두 명 모두 소프트웨어 대학 소속이다. 두 학생이 생물학과라면 모두 자연대학에 속한다. 따라서 department attribute은 school attribute을 결정한다.
- City -> Province 어떤 두 사람이 같은 city에 산다면 두 사람은 같은 도에 사는 것이다.
즉, 두 tuple의 X 값이 같다면 Y 값도 늘 같다. 이는 X -> Y로 표현되고 X의 attribute value가 Y attribute value를 함수적으로 결정한다.
◆ Note that
▪ 만약 어떤 table R에서 X가 candidate key라면
- X -> Y, 어떠한 Y attribute도 함수적으로 결정한다.
- Y는 table R에 속하는 어떤 조합이라도 상관없다. X는 key이기 때문에 이 테이블 안에 X가 같은 tuple은 존재하지 않는다. 따라서 X가 같은 tuple은 하나이고 같은 tuple일 수 밖에 없다. 그렇게 되면 Y값도 당연히 같을 수밖에 없다. 어짜피 같은 tuple이기 때문이다.
▪ X -> Y, X가 Y를 함수적으로 종속시킨다고 해서
- 항상 Y -> X 는 아니다. Y가 X를 함수적으로 종속시키지 않을 수도 있고 종속시킬 수도 있다. 두 사이에 연관성은 없다.
◆ 이러한 FD는 주어진 table schema R의 property이다.
▪ 어떤 특정한 table schema R을 따르는 특정한 table instance r 즉, tuple 들의 집합이 있을 때 해당 집합을 보고 '~~한 FD가 존재하는 것 같아'라고 말할 수 없다.
- FD는 미리 명시하고 FD가 유지되도록 enforce하는 개념이다. FD가 table schema R에 정해지면 이 R을 따른 어떤 table instance도 FD가 지켜져야한다. 예를 들어 department가 단과대학을 functionally determine한다고 한다면 해당되는 학생 table의 어떠한 tuple들이 들어오더라도 이 constraint가 항상 유지되어야한다.
▪ table instance로부터 FD를 유도할 수 없다.
- 먼저 FD를 명시적으로 정의해주고 DB에 들어오는 instance를 지켜지도록 control해야한다. key constraint과 맥락이 동일하다.
◆ Example
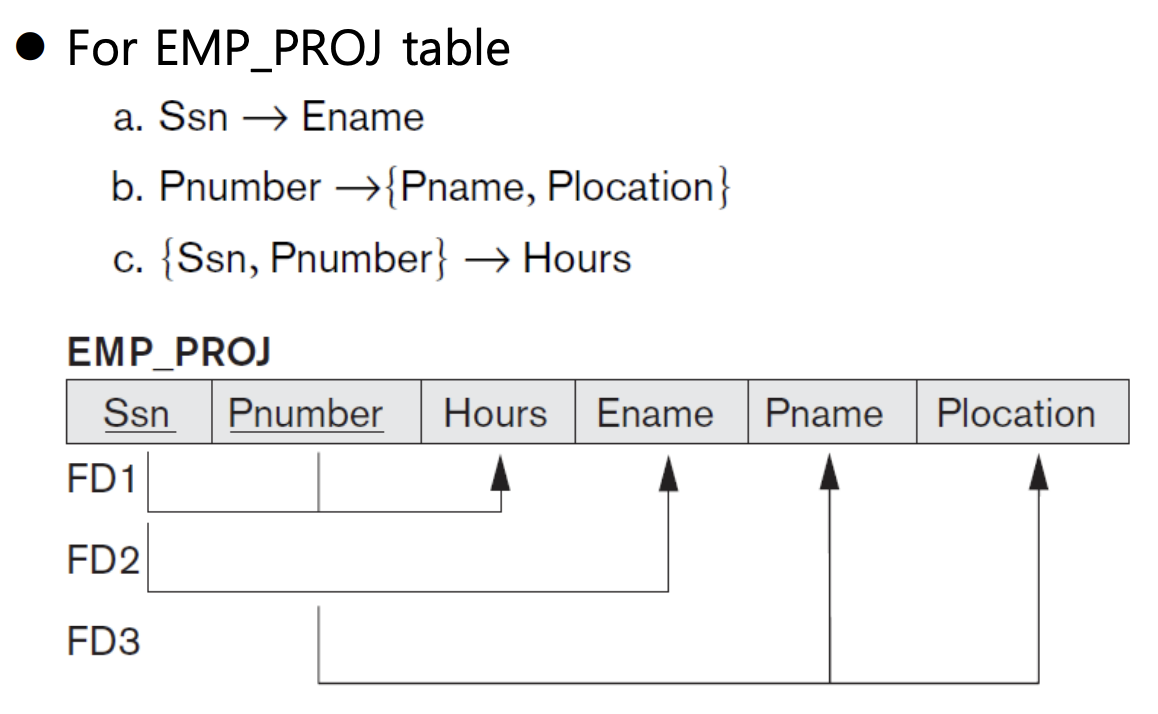
▪ Employee와 Project을 하나의 table로 combine해서 넣은 좋지 않은 테이블이다. 해당 table의 FD는 위와 같다. Ssn이 같은 tuple들은 Ename도 같은 값을 갖는다. 또한, Pnumber가 같은 tuple은 Pname과 Plocation도 같다. Ssn, Pnumber가 같은 tuple은 Hours가 같다. 이는 Ssn, Pnumber가 해당 table 내에서 candidate key이기 때문이다. 따라서 이 값이 같은 tuple은 하나 밖에 없고 당연히 hours 값은 같게 된다.
◆ Inference Rules for FDs
FD를 DB designer가 정의할 수도 있지만 정의되어있는 Functional Dependency를 가지고 정의되어 있지 않은 FD를 유도할 수도 있다.
◆ $F$:
▪ table R에 대해서 정의되어 있는 FD의 집합이다. 위의 예시에서는 3개의 FD를 말한다.
◆ $F^+$:
▪ 주어진 $F$로부터 유추될 수 있는 모든 FD의 집합이다.
▪ $F$를 포함한다.
▪ $F$의 closure라고 한다.
◆ Example
▪ $F$ = {Ssn → {Ename, Bdate, Address, Dnumber}, Dnumber → {Dname, Dmgr_ssn} }
▪ 이를 가지고 추가적인 FD를 추론해낼 수 있다.
- Ssn → {Dname, Dmgr_ssn}
- Ssn → Ssn, Ssn이 같은 두 tuple은 Ssn이 같다.
- Dnumber → Dname
◆ Armstrong’s inference rules
주어진 FD로 부터 새로운 FD를 추론하는 rule에는 3가지가 있다.
▪ IR1 (reflexive rule): If X ⊇ Y, then X→Y
- Y가 X의 subset이면 X는 Y를 함수적으로 종속시킨다. 두 tuple이 있을 때 X값이 같으면 Y는 X의 부분집합이니 당연히 Y값도 같다. 단과대와 학과가 같을 때 Y는 학과이고 X가 단과대와 학과라고 하자. 따라서 단과대와 학과가 같은 tuple은 학과가 같다.
▪ IR2 (augmentation rule): {X→Y} |=XZ→YZ
- X 값이 같으면 Y도 같다. 이것이 사실이면 Z라는 같은 attribute을 집어넣으면 YZ도 같다. 똑같은 attribute을 좌우에 집어넣어도 성립한다.
▪ IR3 (transitive rule): {X→Y, Y→Z} |=X→Z
- X가 Y를 함수적으로 결정하고, Y가 Z를 함수적으로 결정하면 X가 Z를 함수적으로 결정한다. 이는 삼단논법과 비슷하다.
▪ Sound and complete (Proof?)
- 주어진 FD의 집합이 있을 때 Armstrong rule을 적용해서 새로운 rule이 나와도 그 rule은 항상 옳다. 이는 Sound라는 특성이다.
- 이 Armstrong rule을 끊임없이 적용하면 F clousure를 놓침없이 찾을 수 있다. 유도될 수 있는 functional dependency는 더이상 없다.
◆ Other inference rules
▪ IR4 (decomposition rule): {X→YZ} |=X→Y, X→Z
- X가 Y, Z를 functionally determine한다면 X가 Y, Z를 각각 determine한다.
▪ IR5 (union rule): {X→Y, X→Z} |=X→YZ
- X가 Y, Z를 각각 결정한다면 X가 YZ를 결정한다.
▪ IR6 (pseudo-transitive rule): {X→Y, WY→Z} |=WX→Z
- X가 Y를 결정하고 WY가 Z를 결정한다면 WX가 Z를 결정한다. 먼저 양쪽에 W를 집어넣어도 성립한다. WX -> WY이고 WY -> Z이기 때문에 transitive rule을 적용하면 WX -> Z가 됨을 알 수 있다. augmentation rule과 transitive rule을 적용한 결과이다.
▪ Can prove IR4~6 by using IR1~3, Armstrong's inference rule을 가지고 모두 증명할 수 있다.
- 또한 Armstrong's inference rule 만을 가지고도 F closure를 모두 구할 수 있다.
◆ Systematic Way to Determine Additional FDs
◆ $X$:
▪ FD에서 화살표의 왼쪽에 존재하는 attribute의 집합
◆ $X^+$:
▪ $F$라는 FD 집합 하에서 X가 결정할 수 있는 attribute들을 X closure라고 한다.
▪ $F$라는 FD 집합 하에서 $X$의 closure라고 한다.
▪ 각각의 $X$에 대해서 결정된다.
▪ X라는 attribute set이 있을 때 functional dependency를 반복적으로 적용해서 계산된다.
◆ $X^+$을 결정하는 알고리즘

주어진 $X$와 FD set $F$ 하에서 X의 closure를 구하고 싶다.
처음에 주어진 $X$가 있으면 그 안의 attribute를 X closure $X^+$에 넣는다. 그 후 현재가 가지고 있는 $X^+$를 old$X^+$안에 집어 넣는다. $F$안에 들어있는 $Y -> Z$가 있다고 하자. 만약 $Y$가 $X^+$의 원소이면 현재 들고 있는 $X^+$에 Z라는 attribute를 추가한다. 다음 FD에도 지속적으로 적용해서 $X^+$를 점점 늘려나간다. $X^+$가 커졌으면 old$X^+$와 같지 않으니 그 $X^+$를 old$X^+$로 만들고 다시 FD를 check한다. 이를 old$X^+$와 이번 iteration을 통해 만들어진 $X^+$가 같을 때까지 반복한다. 그때 나온 X closure는 $X$에 의해서 현재가지고 있는 모든 functional dependency를 적용해서 나올 수 있는 모든 attribute의 집합이다.
◆ Example

Ssn이 있을 때 Ssn의 closure를 구하고 싶다. Ename이 Z이다. Ssn과 Ename을 왼쪽에 동시에 가지고 있거나 하나만 가지고 있는 FD가 없으니까 Ssn의 closure는 Ssn과 Ename이다.
◆ Summary
◆ Informal guidelines for good design
◆ Functional dependency
▪ Basic tool for analyzing relational schemas
▪ Inference rules
'3-2 > 데이터베이스시스템' 카테고리의 다른 글
| [DB14] Relation Decomposition과 Algorithms (8) | 2024.11.28 |
|---|---|
| [DB13] Normal Form과 Normalization (4) | 2024.11.21 |
| [DB10] INSERT, DELETE, UPDATE SQL 파헤치기 (1) | 2024.11.12 |
| [DB09] Nested query, Aggregate function, Grouping등 SQL 파헤치기 (1) | 2024.11.11 |
| [DB08-2] SQL 알아보기_SELECT/FROM/WHERE (2) | 2024.11.04 |