seq2seq 모델
인코더-디코더 구조를 따르며 입력 시퀀스가 주어졌을 때 그에 해당하는 출력 시퀀스를 생성하는 방식으로 작동한다. Encoder에서는 입력 시퀀스를 받아 내부의 고정된 크기의 컨텍스트 벡터로 변환한다. Decoder에서는 encoder에서 생성된 context vector를 받아 출력 seqence를 하나씩 생성한다.
RNN(Recurrent Neural Network)
입력과 출력을 시퀀스 단위로 처리하는 시퀀스 모델
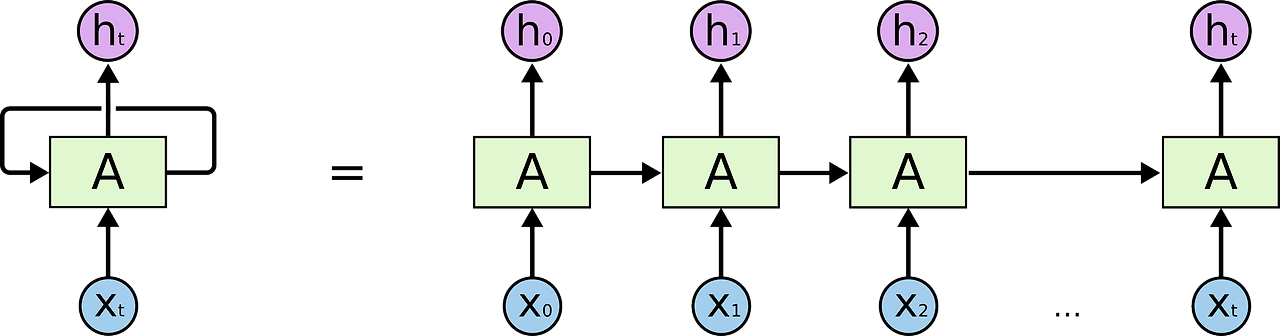
RNN은 시퀀스 데이터를 처리하기 위해 설계된 신경망 모델이다. 시퀀스 데이터는 순서가 중요한 데이터로 가장 대표적인 예로 자연어 처리에서의 문장이 있다. 한 번에 하나의 데이터를 처리하면서 이전의 데이터를 기억하고 이를 반영하여 결과를 출력한다. 과거의 신경망들은 보통 은닉층에서 출력층 방향으로 향했다. 이를 Feed Forward Neural Network라고 한다. 다만 RNN은 은닉층의 노드에서 활성화 함수를 통해 나온 결과 값을 출력층 방향과 은닉층 노드의 다음 계산의 입력으로도 보내는 특징을 가지고 있다. 다만 긴 시퀀스 데이터를 처리할 때 gradient vanishing 문제로 인한 문제가 있다. 과거에 알던 정보를 찾으러 계속 전으로 가다보면 기울기 소실 문제가 생기는 것이다.
LSTM(Long Short-Term Memory)
RNN의 문제점을 개선하기 위해 생긴 모델이다. 때문에 긴 시퀀스의 데이터를 잘 처리할 수 있도록 설계되었다. 은닉층 외에도 Cell state를 추가해서 긴 시퀀스의 정보를 잘 저장할 수 있도록 하였다. 또한 gate에 의해서 정보를 어디에 저장하고 언제 읽고 언제 버릴지 결정이 되어 장기적인 의존성을 처리한다.
GRU(Gated Recurrent Unit)
LSTM과 유사한 역할을 하지만 은닉 상태 업데이트를 하는 계산을 줄인 간단한 모델이다. 게이트를 업데이트 게이트, 리셋 게이트로 2개만을 사용하여 계산하여 계산 비용이 적지만 성능 면에서 LSTM과 큰 차이가 없다. forget gate, input gate를 하나로 합해서 update gate로 바꾼 것이다.
위의 seq2seq 모델은 Encoder-Decoder 구조로 구성되어 있으며 encoder가 입력 시퀀스를 하나의 벡터로 압축하는 과정에서 입력 시퀀스의 정보가 일부 손실된다는 문제가 있었다. 이를 해결하기 위해 attention을 추가하여 RNN을 보정하는 용도로 사용했다.
Transformer

Transformer는 구글이 발표한 논문 "Attention is all you need"에서 나온 모델로 인코더-디코더를 따르면서도 단어와 단어 간의 상관관계를 찾아 Attention을 계산하여 구현한 모델이다. 입력 시퀀스를 하나의 벡터로 압축하지 않고 모든 시점의 정보를 동적으로 고려할 수 있도록 만들어서 모든 단어가 서로 영향을 미칠 수 있도록 하였다. 또한 이전 모델들은 시퀀스 데이터를 순차적으로 처리해야 했기 때문에 각 단어를 처리할 때 이전 단어의 계산을 기다려야 했다. 이로 인해 훈련 속도가 느리고 병렬 처리가 어려운 문제가 있었다. 이를 해결하기 위해 transformer에서는 각 단어를 동시에 처리할 수 있게 설계되어 병렬 처리가 가능하도록 설계되어 과거에 비해 훈련 속도가 크게 늘어났다.
We want to train this architecture to convert English to French. The transformer consists of two components, an Encoder and a Decoder. The encoder takes the words simultaneously and generates embeddings for every words simultaneously. These embeddings are vectors that encapsulate the meaning of the words. Similar words have closer numbers in their vectors. The decoder takes this embeddings from the encoder and the previously generated words of the translated French sentence. Then it uses them to generate the next French word. And we keep generating the french translation one word at a time until the end of sentence is reached. What makes this conceptually so much more appealing than some LSDM cell, is that we can physically see a seperation in tasks. The encoder learns what is English, what is grammar and more importantly what is context. The decoder learns how do English words relate to French words. Both of these, even separately, have some underlying understanding of language. And it's because of this understanding that we can pick apart this architecture and build systems that understand language. We stock the decoders and we get the GPT transformer architecture, conversely if we stack just the encoders, we get BERT. A Bidirectional Encoder Representation from Transformers.
The og transformer has language translation on lock but we can use BERT to learn language translation, question answering, sentiment analysis, text summarization and many more tasks. All of these problems require the understanding of language. So we can train BERT to understand language and then fine tune BERT depending on the problem we want to solve. Training of BERT is done in two phases. The first phase is pre-training where the model understands what is language and context, and the second phase is fine tuning where the model learns 'I know language, but how do I solve problem.'
'Paper Review' 카테고리의 다른 글
| [Paper Review] Dense Passage Retrieval for Open-Domain Question Answering (0) | 2025.01.10 |
|---|---|
| [논문 리뷰] DeBERTa: Decoding-enhanced BERT with Disentangled Attention (3) | 2025.01.03 |
| BERT의 구조 이해하기 (4) | 2024.12.26 |
| [논문리뷰] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2) | 2024.12.26 |
| Multi Agent Reinforcement Learning (1) | 2024.12.24 |