[DB14] Relation Decomposition과 Algorithms
* 12.18 업데이트
해당 게시물은 한양대학교 컴퓨터소프트웨어학부 김상욱 교수님 데이터베이스시스템 온라인 강의를 듣고 정리한 자료입니다.
오류가 있다면 언제든 알려주세요!
● 해당 강의의 목표
1. formal한 relation database design algorithms를 알아본다.
▪ relational decompositions의 properties
▪ relational database design algorithms
◆ Relation Decomposition
◆ Relational database design by decompositon (ER model -> Relation mapping으로 해도 가능하다.)
1. Universal relation schema에서 시작한다.
▪ Univeral relation schema란 해당 database의 모든 속성들을 포함한 relation schema $R = {A_1, A_2, ..., A_n}$이다.
▪ 모든 attribute 이름은 unique하다. 하나의 table에 있기 때문에 이름이 같으면 안 된다.
2. R을 쪼개서 여러개 의 relation schema로 만든다. $D = {R_1, R_2, ..., R_m}$
▪ 각각의 relation $R_i$는 universal relation schema $R$에 포함되었던 attribute들의 subset을 가지고 있다.
▪ universal relation schema $R$에 속했던 각 attribute는 $R_i$ 중 적어도 하나에는 나타나야 한다. 하나의 attribute이 두 개 이상의 $R_i$에 나타날 수 있다. 이는 join을 위해서 필요하다.
▪ 각각의 table $R_i$는 BCNF 또는 3NF이어야 한다. 중복이 없는 좋은 형태의 table이 된다.
- BCNF가 3NF보다 더 좋은, 중복을 없애는 구조인데 왜 or 인가요? BCNF로 만들 수 없는 경우도 있나요?
YES. 항상 BCNF로 만들 수 있지 않기 때문에 3NF도 허용하는 것이다.
▪ 이렇게 형성된 여러 table을 가진 $D$를 $R$의 decomposition이라고 한다.
◆ Insufficiency of Normal Forms
◆ 결과적으로 쪼개진 $R_i$ 각각이 BCNF 또는 3NF만 만족하면 되는 것인가요?
◆ NO! Normal form으로 쪼개는 것만으로 완벽하지 않다. 추가적인 조건이 있다. 이를 normal form의 불충분성이라고 한다.
◆ 전체 $R$을 2개의 attribute을 가지는 table로 다 쪼개면 각각의 테이블은 자동적으로 BCNF가 된다. BCNF란 'table에 적용되는 FD가 있을 때 FD의 왼쪽 part는 superkey이어야 한다'인데 2개의 attribute을 가진 table은 그 조건을 만족하기 때문이다.
◆ 따라서 어떠한 universal relation schema라도 2개의 attribute을 갖게끔 다 쪼개버리면 BCNF가 되어 앞의 조건을 모두 만족하게 된다.
▪ 하지만 이 조건을 만족한다고 해서 좋은 relation schema라고 부를 수 없다. Spurious tuple, 가짜 tuple들이 등장하기 때문이다.
◆ Example: spurious tuples

▪ 위의 예시에서 두 개의 table을 join하면 어떤 이름의 사람이 어떤 위치에서 일하고 프로젝트 이름 등을 알 수 있다. 이를 join하려면 공통인 attribute이 있어야 하고 해당 예시에서는 Plocation이 된다. 이를 join하면 다음과 같은 결과가 나온다.
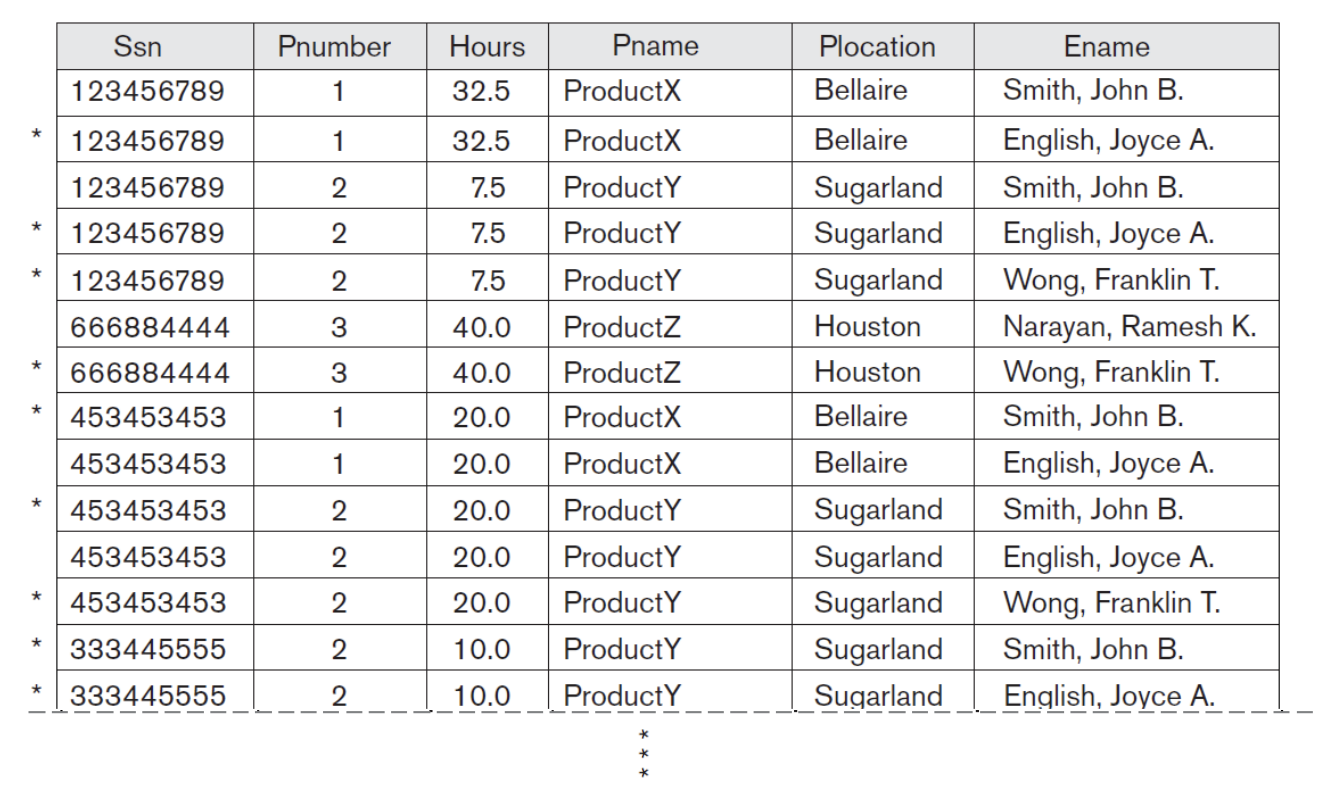
▪ 하지만 옆에 별이 있는 tuple은 원래 tuple에 나타나지 않는 tuple이 나타난다. 실제로 해당 employee가 해당 project에서 일하지 않는데 location이 우연히 같아서 가짜 tuple이 나타나는 것이다. 두 테이블을 잘못 쪼개서 나타낸 table을 또 잘못 join해서 생기게 된다.
▪ 따라서 가짜 tuple이 나타나지 않는 방법으로 decomposition 해야한다.
◆ 좋은 relational databases를 위한 추가적인 특성
▪ 정보를 잃지 않게 join이 되도록 decompose 되어야한다. 잘못된 정보가 추가로 나오는 것을 Loss로 보는 것이다.
▪ functional dependency가 보존되도록 decomposition을 해야한다.
▪ 따라서 Normal Form으로 각각을 만드는 것이 맞지만 결과적으로 normal form만 되는 것이 아니라 그것이 lossless join이 되도록 decomposition된 후에 NF이 되어야하고 FD가 보존되어야한다는 것이다.
◆ Dependency Preservation
◆ $F$: universal relation schema $R$이 있고 여기에 정의되는 Functional Dependency이다.
◆ Dependency preservation의 조건
▪ Decompostition된 $D$가 functional dependency를 preserve해야 한다.
▪ $D$에 속하던 $R_i$들이 가지고 있는 functional dependency를 $F_i$를 union한 것이 원래의 $F$와 같다면 이 decomposition이 dependency preservation property를 만족하는 decomposition이라고 한다.
◆ Formal definition
▪ $F$를 $R_i$ (universal relation schema의 decomposition에 속하는 하나의 table)에 projection == $\pi_{Ri}$$(F)$
- $R_i$에 포함된 attribute으로만 구성된 functional dependency만을 뽑아낸 것이 바로 $F$를 $R_i$에 projection한 것이라고 한다.
▪ 각각의 $R_i$에 projection한 결과들을 union한 것의 closure가 universal relation schema의 FD set의 closure와 같다면 분리된 $R_i$가 가지고 있던 functional dependency를 다 합한 것이 original functional dependency set과 동일한 것이다. 그랬을 때 우리가 나눈 Decomposition $D$는 dependency를 잘 보존하고 있는 것이라 한다. $D$로 나눌 때 나누어진 결과 각각의 $R_i$가 BCNF이거나 3NF이어야 하고 이렇게 나눈 decomposition이 dependency를 preserve하고 있어야 한다.
$((\pi_{R1}(F) )\cup ... \cup (\pi_{Rm}(F) ))^+ = F^+$
◆ 각각의 dependency가 constraint이기 때문에 무조건 guarantee되어야 한다. X가 Y를 functionally dependent하고 있는지의 여부가 보장되어야 한다. 즉, update이 일어났을 때 X가 Y를 functionally dependent하고 있는가에 위배되지 않았는지를 계속 확인해 주어야 한다.
◆ 만약 어떤 decomposition이 dependency-preserving하지 않으면, 즉, 어떤 dependency X가 Y를 결정한다는 것이 X와 Y가 2개의 table로 이루어져 있을 때 dependency preservation이 깨지는 것이다. 하나 안에서 되지 않고 2개 이상의 table을 거쳐서 dependency가 존재하는 것이다.
▪ 이 경우 두 개의 table을 join해서 dependency가 hold되는지 결과를 가지고 확인해야 한다.
▪ Join은 시간이 걸리는 operation이기 때문에 효율적이지 못하다. 따라서 실질적으로 사용하기 어렵다. 따라서 쪼갤 때 dependency preservation이 깨지지 않도록 해야한다.

3NF은 주어진 FD에서 왼쪽에 있는 것이 superkey이거나 오른쪽에 있는 것이 prime attribute이어야한다. FD5은 왼쪽이 superkey가 아니기 때문에 BCNF가 아니다. 하지만 오른쪽에 있는 County_name이 prime attribute이기 때문에 3NF이다. 이를 BCNF로 만들기 위해서는 Area와 County_name을 빼서 새로운 table로 만들어야하고 오른쪽에 있는 County_name을 빼야한다. Area는 그대로 둬서 join attribute이 된다. 이렇게 쪼갬으로써 table이 BCNF가 되어 더 좋은 Normal form이 되었다. 문제는 FD2이다. 왼쪽의 것을 LOTS1AX, LOTS1AY에서 형성할 수 없기 때문에 항상 두 table을 join해서 FD2를 hold하는지 확인해야한다. 따라서 잃은 것은 functional dependency가 preserve되지 않는 점이다. 즉, effidency 측면에서 문제가 생긴다. 따라서 바람직한 형태를 3NF도 가능하다고 한 것이다.
◆ Relational Decomposition into 3NF with Dependency Preservation
◆ Universal schema $R$에 적용되는 전체 FD set인 $F$의 minimal cover $G$
▪ $F$와 동일한 functional dependency의 집합이다. 즉, $G^+ = F^+$이다. 생긴 것은 다르지만 의미상으로는 F와 똑같은 의미의 Functional Dependency 다.
▪ $F$에서 필요없는 것을 다 제거한 것으로 이해할 수 있다. $G$에서 FD자체든, attribute이든 어떤 것이든 하나라도 제거하면 더 이상 F와 동일하지 않게 된다.
◆ $F$에서 minimal cover $G$를 어떻게 찾을까.
▪ $F$에 존재했던 각 FD들을 canonical form으로 바꾼다.
- 이는 오른쪽에 하나의 attribute만 두는 형태를 말한다. A -> B, C라면 A -> B, A -> C로 나누는 것이다.
▪ Canonical form인 FD의 왼쪽 side에서 필요없는 속성을 제거한다.
- XY -> A가 있을 때 Y를 제거하면 X -> A가 된다. 다른 FD와 X -> A로 XY -> A를 유도할 수 있다면 Y를 제거할 수 있다. Y의 도움없이 X가 A를 결정한다는 것과 다른 FD로 XY가 A를 결정할 수 있다면 Y가 필요 없다는 것이다. 이렇게 왼쪽의 불필요한 것을 다 제거한다.
▪ F에서 불필요한 FD를 제거한다.
- XY -> A를 제거해 보고 다른 FD에서 XY가 있다면 이 XY가 A를 functionally dependent하는가 확인을 한다. 이것이 증명되면 해당 FD를 제거한다. X -> Y, Y -> Z 일 때 X -> Z가 있다면 이는 더 이상 필요가 없다. 앞의 두 FD로 유도할 수 있기 때문이다. 이렇게 남겨진 FD의 set이 $F$에 대한 minimal cover $G$가 된다. 이를 통해 주어진 relation을 Dependency Preservation을 만족하는 3NF로 바꾸는데 활용한다.
◆ 3NF이면서 original uninversal relation schema에 대한 dependency를 보장하도록 relation을 decompose 알고리즘
1. 주어진 F에 대한 minimal cover $G$를 구한다.
2. $G$에 있는 FD 중 왼쪽에 있는 X를 모두 고른다.
- ${{X \cup A_1 \cup A_2 ... \cup A_K}}$ $X$와 그 FD의 오른쪽에 있는 attribute을 모두 묶어서 하나의 새로운 relation schema로 만든다.
새롭게 만들어진 table에서 key는 $X$이다. 따라서 이는 3NF를 만족한다. 나머지 FD에서 또다른 왼쪽이 동일한 FD를 골라서 다 모아서 새로운 테이블을 만들고 이를 반복한다.
3. 이렇게 FD를 다 뺐는데 여전히 attribute이 남아있다면 이는 FD에 포함되어 있지 않아서 table로 만들 수 있는 여지가 없다. 이들을 다 모아서 하나의 relation schema에 넣는다. 만약 남은 attribute을 버렸다면 원래 relation schema와 달라져서 attribute preservation property를 만족하지 않게되니 버리면 안 된다.
이러한 작업을 통해 만들어진 table들은 적어도 3NF이고 dependency가 preserved된다.
◆ Lossless Join Property
◆ non-additive join property라고도 불린다. 추가되는 tuple이 없기 때문이다.
◆ 하나의 table을 2개 이상의 table로 쪼갠 다음에 이들을 다시 join한다고 하자. 이때 원래 table에 존재하지 않는 spurious tuple들이 전혀 나타나지 않도록 보장되는 decomposition을 lossless join property를 가진 decomposition이라고 한다.
◆ Formal definition
▪ original relation $R$이 있을 때 이의 decomposition $D = {R_1, R_2, ..., R_m}$이 있다고 하자. m개의 table로 쪼갠 것이다. 이 것이 lossless join property를 갖는다의 의미는
- original relation R에 속하는 어떠한 table instance도 $(\pi_{R1}(r), ..., \pi_{Rm}(r)) = r$을 만족한다. 모든 $R_1~ R_n$에 속하는 attribute를 가지고 projection한 각각의 table instance가 있을 때 이들을 join하면 원래의 table instance r이 나온다.
- r은 R에 속하는 어떤 table instance이다. 원래 table instance로 완전히 recover되는 것이 decomposition이 lossless join property를 갖는다고 한다.
◆ Relational Decomposition into BCNF with Lossless Join Property
◆ BCNF이면서 original uninversal relation schema에 대한 dependency를 보장하도록 relation을 decompose 알고리즘 (BCNF가 아니면 BCNF가 되도록 쪼갠다.)
1. Set $D := {R};$ R을 BCNF로 만들고 싶은 상황이다.
2. D안에 들어있는 relation schema Q가 BCNF가 아니라면
Q(여러 개라면 그 중 하나를 고른다.)에서 BCNF를 위반하는 Functional dependency X -> Y를 찾는다. 그 후 Q를 (Q - Y) 와 (X U Y) table로 바꾼다. (Q - Y)는 BCNF가 될 가능성이 있는 것이고 (X U Y)는 BCNF이다. X가 key이다. 즉, Q를 BCNF가 되지 못하도록 하는 FD를 찾아서 그것을 묶어서 하나의 table로 만들고 오른쪽에 있는 Y를 원래 table에서 빼준다. 여전히 (Q - Y)는 BCNF가 되지 않을 수도 있다. 더 이상 BCNF가 아닌 것이 없을 때까지 반복하고 결국 Original table $R$은 BCNF형태로 나눠진다.
Q. 이렇게 하면 왜 lossless join property를 만족할까?
◆ 이 알고리즘이 기반을 두고 있는 lossless join property의 두 특성
▪ 어떤 table $R$을 $D = {R_1, R_2}$로 나눴을 때 두 table이 $R$에 있는 FD의 집합인 $F$에 대해 lossless join property를 만족하려면 다음과 같은 두 조건을 만족해야한다.
- The FD $((R_1 \cap R_2)→(R_1 – R_2))$ is in F^+, or $R_1$과 $R_2$의 교집합이 $R_1 - R_2$를 함수적으로 종속시켜야 한다.
▪ The FD $((R_1 \cap R_2)→(R_2 – R_1))$ is in $F^+$ $R_1$과 $R_2$의 교집합에 해당되는 attribute이 $R_2 - R_1$를 함수적으로 종속시켜야한다.
둘 중에 하나를 만족하면 해당 decomposition은 lossless join property를 만족시킨다. 즉, $R_1$과 $R_2$를 join하면 항상 $R$의 원본을 가짜 tuple없이 회복시킬 수 있다.
$((R_1 \cap R_2)→(R_1 – R_2))$은 $R_1$ 고유의 attribute을 함수적으로 종속시킨다는 것, 즉, 교집합이 $R_1$의 key라는 말이다. 교집합이 $R_1$의 key라는 것은 $R_2$에도 존재한다는 것이다. 이는 교집합인 attribute가 $R_1$에서는 key이고 $R_2$에서는 FK라고 해석할 수 있다.
$((R_1 \cap R_2 )→(R_2 – R_1))$는 교집합인 attribute가 $R_2$의 key, $R_1$의 FK라는 뜻이다.
$R_1$과 $R_2$의 교집합이 $R_1−R_2$ (즉, $R_1$에만 있는 속성들)를 함수적으로 종속시켜야 한다는 의미이다.
▪ 즉, key와 FK 관계가 되도록 나누면 lossless join property를 만족한다는 것이다. 따라서 나눌 때 key, Fk pair로 나눠야한다.
▪ Q. (Q - Y) 와 (X U Y) 이것이 key, foreign key로 나누는 것일까?
A. Yes!
X -> Y이기 때문에 X가 candidate key가 된다. 또한 (Q - Y)에서는 Y만 빼고 X가 존재하기 때문에 X가 FK로 존재하는 것이다.
▪ R의 decomposition $D = {R_1, R_2, ..., R_m}$이 lossless join property를 만족시킨다면
▪ 이 table 중 하나인 $R_i$를 다시 $D_i = {Q_1, Q_2, ..., Q_k}$로 decomposition하고 lossless join property를 만족한다면
▪ 결과적으로 $D_2 = {R_1, R_2, ..., R_{i-1}, Q_1, Q_2, ..., Q_k, R_{i+1}, ..., R_m}$인 decomposition을 얻게 된다. 이 또한 전체가 lossless join property를 만족한다. 앞의 알고리즘에 의해서 반복해서 나눈 D가 BCNF가 되고 lossless join property를 만족하게 하는 decomposition이다.
◆ Dependency Preservation and Lossless Join Property
◆ Relational decomposition을 해서 BCNF를 만들고 dependency preservation이 되고 lossless join property가 되고 이 모든 것을 다 되게하는 알고리즘이 있으면 좋다. 대부분의 경우 된다. 하지만 항상 되는 것은 아니다.
▪ BCNF
▪ Dependency-preserving
▪ Lossless join
이 세가지를 만족시키지 못하는 경우가 있다.
▪ Counter example

- A, B가 해당 table의 candidate key이다.
- C는 A를 functionaly dependent하게 만들 수 없기 때문에 key는 아니다.
- R은 3NF이다.
- FD2가 존재하기 때문에 BCNF는 아니다. FD2가 BCNF를 violate하는 FD이다.
- BCNF를 만들기 위해선 A, B, C를 쪼개서 A, C(C: FK)와 B, C(C: PK)로 만들면 lossless join이 만족된다. 하지만 FD1이 preserve되지 않는다. 따라서 그대로 두면 dependency preservation과 lossless join property를 만족하지만 3NF이다. 반면 나누면 lossless join property와 BCNF가 만족되지만 dependency preservation이 만족되지 않는다. 이러한 상황에 빠지는 경우가 가끔있다. 이러한 경우는 결정을 해야한다.
◆ Dependency preservation과 lossless join을 하고 쪼개지 말고 3NF으로 만드는 알고리즘
1. F에서 minimal cover $G$를 찾는다. (minimal cover: 오른쪽에는 attribute 하나만 있다.)
2. $G$안에 있는 FD의 왼쪽에 있는 같은 X들을 다 모아서 하나의 table $D$로 만든다. 이를 반복한다. 앞에서는 남은 attribute들을 모아서 하나의 table로 만들었다. 해당 경우는 다르다.
3. $R$의 key에 해당되는 attribute이 $D$ 내에 있는 어떠한 schema에 해당되지 않는다면 하나의 table을 만들어서 original table $R$의 key attribute을 모두 집어넣어라.
◆ key를 찾는 알고리즘
주어진 table에서 FD set $F$가 있을 때 해당 table의 candidate key를 찾을 수 있다. 원래 candidate key는 유일하게 tuple들을 식별할 수 있게하는 attribute의 집합이다. 그렇게 정의할 수도 있지만 dependency의 의미를 가지고 정의할 수 있다.
key: relation $R$에 있는 다른 attribute를 functionally determine할 수 있는 attribute이다. key에 해당되는 attribute가 같으면 다른 attribute가 모두 같다.
1. $K := R;$ key에 해당되는 것에 Relation $R$에 해당되는 모든 attribute를 넣는다.
2. $K$에 있는 각각의 attribute $A$에 대해서 $(K - A)$에 $F$를 적용해서 $(K-A)^+$ ($(K-A)$에 의해서 함수적으로 종속될 수 있는 attribute들의 집합)을 찾는다. 만약 $(K-A)^+$가 $R$의 모든 attribute들을 포함한다면 $K$에서 $A$를 빼더라도 나머지 attribute을 함수적으로 결정할 수 있다. 즉, attribute $A$는 candidate key가 아니다. 따라서 $K$에서 $A$는 필요가 없으니 $K := K - {A};$가 된다. 만약 모든 attribute를 포함하지 않는다면 빼려고 했던 $A$는 필요한 attribute이기 때문에 다시 넣어주어야한다. 이를 반복하면 $R$의 모든 attribute을 functionally determine하는데 필요한 attribute만 남게된다. 그것이 바로 key가 되는 것이다.
◆ 대부분의 3NF는 BCNF이다. counter example이 BCNF가 아닌 거의 유일한 예이다.
◆ Summary
1. Relation decomposition
▪ Dependency preservation
▪ Lossless join property
2. Algorithms
▪ 3NF decomposition with dependency preservation
▪ BCNF decomposition with lossless join property
▪ 3NF decomposition with dependency preservation and lossless join property
1. 3NF + Dependency Preservation
설명
- **Minimal Cover $G$**를 찾는다.
- $G$는 $F$에서 중복되지 않는 최소한의 함수 종속성을 나타냄.
- 각 FD에 대해 테이블 생성:
- $G$에 있는 FD에서 왼쪽 X와 그 FD의 오른쪽 속성(종속되는 속성)을 하나의 테이블로 묶어서 테이블 생성.
- 이 과정은 $G$의 모든 FD를 처리할 때까지 반복.
- 남은 속성 처리:
- $G$의 FD에서 처리되지 않은 속성들을 하나의 테이블로 묶음.
- 이를 통해 **속성 보존(Attribute Preservation)**을 보장.
특징
- Dependency Preservation: 각 FD가 보존됨.
- Lossless Join은 기본적으로 보장되지 않을 수 있음.
- 결과는 3NF로 분해된 테이블.
2. BCNF + Lossless Join Property
설명
- 테이블 $R$ 전체를 BCNF로 변환하려는 목표를 설정 ($D:={R}$).
- BCNF를 위반하는 FD $X를 찾음.
- 위반된 FD를 기준으로 테이블을 분해:
- $Q$: 원래 테이블 중 BCNF를 위반한 스키마.
- $(Q−Y: $Y$ 속성을 제외한 나머지 속성.
- $(X \cup Y): $X$와 $Y$를 포함하는 새로운 테이블. 이 테이블은 항상 BCNF를 만족.
- 위 과정을 반복해 더 이상 BCNF를 위반하는 테이블이 없으면 종료.
특징
- Lossless Join: 항상 보장.
- Dependency Preservation: 보장되지 않을 수 있음 (필요 시 재구성).
3. 3NF + Dependency Preservation + Lossless Join Property
설명
- Minimal Cover $G$를 찾는다:
- 함수 종속성을 최소화(중복 제거).
- 각 $X$-기반 테이블 생성:
- $G$의 FD를 기준으로 $X→{A_1,A_2,...,A_k}$에 따라 테이블 생성.
- 각 테이블의 키는 FD의 왼쪽 $X$이다.
- 키 보존:
- 만약 $R$의 키가 만들어진 테이블들 중 어디에도 완전히 포함되지 않았다면, 키 속성들로 구성된 새로운 테이블을 추가.
특징
- Dependency Preservation: 보장됨.
- Lossless Join: 보장됨.
- 결과는 3NF로 분해된 테이블.