[Paper Review] Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Abstract
Chain-of-thought (CoT) prompting이 다양한 자연어 추론 작업에서 뛰어난 성능을 보이지만 주어진 예제보다 더 어려운 문제를 해결하는 능력에서는 한계를 보인다. 이를 해결하기 위해 저자는 Least-to-Most prompting이라는 새로운 프롬프팅 기법을 제안한다.
핵심 아이디어는 복잡한 문제를 일련의 더 간단한 하위 문제로 나눈 뒤 이를 순차적으로 해결하는 것이다. 이전 단계에서 해결한 하위 문제의 답을 활용하서 다음 하위 문제를 풀어나가면서 최종적으로 원래의 복잡한 문제를 해결하는 방식이다. 실험 결과 기호 조작, compositional generalization, 수학적 추론 등의 작업에서 Least-to-Most prompting이 기존 방법보다 더 어려운 문제를 해결하는 데 효과적이었다.
특히 GPT 3 code-davinci-002 모델을 사용하여 SCAN이라는 compositional generalization 벤치마크 테스트를 수행한 결과 이 방법을 적용하였을 때 모든 데이터 분할에서 99% 이상의 정확도를 달성하였다. 이는 CoT를 적용했을 때의 정확도(16%)에 비해 현저히 높은 성능이다.
기존 neural-symbolic 모델들은 SCAN을 해결하기 위해 15,000개 이상의 학습 데이터를 필요로 했던 반면 해당 프롬프팅은 14개의 예제만으로 굉장히 높은 정확도를 달성했다는 점에서 의의가 있다.
Instruction
It consists of two stages: first decomposing a complex problem into a list of easier subproblems, and then sequentially solving these subproblems, whereby solving a given subproblem is facilitated by the answers to previously solved subproblems.
1. 복잡한 문제를 더 쉬운 하위 문제 목록으로 분해한다.
2. 이 하위 문제들을 순차적으로 해결하는데 이때 이전 단계에서 해결된 하위 문제의 답을 활용하여 다음 하위 문제를 푸는 방식으로 진행된다.
두 단계 모두 few-shot prompting을 사용하여 구현되므로 어느 단계에서도 별도의 학습이나 미세 조정이 필요하지 않다.

Least-To-Most prompting
1. Decomposition
주어진 문제를 어떤 방식으로 분해할지에 대한 예시를 프롬프트로 제시한다. 모델은 이러한 예시를 참고해서 주어진 문제를 여러개의 하위 문제들로 쪼갠다.
2. Subproblem Solving
분해된 하위 문제들을 하나씩 순차적으로 해결하는 과정이다.
Figure 1
1. Decomposition
언어 모델에 이 문제를 하위 문제로 나누어라라고 요청
모델은 문제를 분해한 후 "How long does each trip take?"라는 중간 문제를 생성함.
2. Subproblem Solving
모델이 첫 번째 하위 문제에 대한 답인 "each trip takes 5 minutes"를 생성함
위의 답을 새로운 프롬프트에 추가하고 다음 하위 문제를 모델에게 제시함
이 과정이 반복되면서 마지막에 원래의 복잡한 문제까지 해결됨.
Results
해당 논문에서는 symbolic manipulation, compositional generalization, math reasoning 작업에서 결과를 제시하고 CoT prompting과 결과를 비교하였다.
1) Symbolic Manipulation
주어진 단어들의 맨 끝 글자를 합치는 'last-letter-concatenation task'로 실험을 진행하였다.
기존의 방법론을 적용한 경우 few-shot에 포함된 예시들의 길이가 풀고자 하는 실제 문제의 길이보다 짧을 때 generalization 성능이 크게 하락하였다.
Least-to-Most prompting

1. Decomposition
Table 1과 같이 큰 리스트를 작은 하위 리스트들로 나누는 방법을 보여준다.
2. Subprobleming Solving
각 하위 리스트를 원하는 출력으로 변환하는 방법을 설명해준다. 새로운 하위 리스트가 주어지면 이를 Table 2에 추가하여 해결 프롬프트를 생성한다.
이전 단계에서 생성된 답이 지속적으로 추가되어 옳은 정답을 뽑을 수 있도록 유도한다.
가장 최근의 응답을 최종 해결책으로 사용한다.
Chain-of-thought prompting

앞선 예시처럼 이전 문제의 출력을 활용하여 새로운 문제를 해결하는 것이 아니라 각 문제의 답을 처음부터 새로 계산한다.
Results
이 실험에서는 Wiktionary에서 무작위로 단어를 샘플링하여 길이가 4에서 12까지 다양한 test list를 생성했다.
실험 대상 모델은 code-davinci-002 (GPT-3)이며 세 가지 프롬프팅 기법의 성능을 비교하였다.
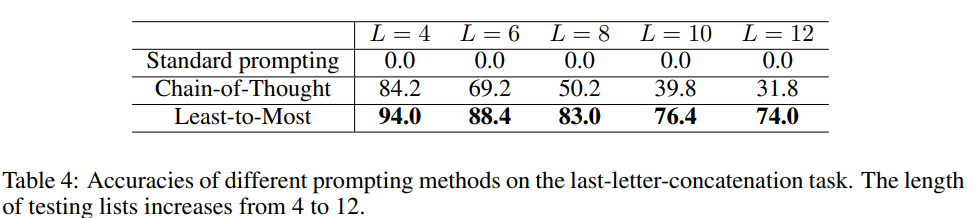
기본 Few-shot 프롬프팅의 정확도는 0%로 중간 추론 과정 없이 단순한 예제만 제공하면 모델이 일반화하지 못한다는 것을 알 수 있다.
CoT prompting은 list의 길이가 길어질수록 성능이 급격히 덜어진다는 것을 확인할 수 있다.
LtM prompting은 list의 길이가 길어질수록 성능 저하가 적게 발생하는 것을 보아 보다 복잡한 문제에도 더 잘 일반화됨을 확인할 수 있다.
LTM prompting이 더 많은 단어를 포함하기 때문에 성능이 더 높았을 가능성을 염두하고 추가 실험을 진행하였다.
CoT에서도 LTM과 동일한 예제 길이를 사용하도록 조정하여 테스트를 해서 예제 개수를 늘려 프롬프트 길이가 같은 조건에서도 LTM이 더 나은 성능을 보이는지 평가했다.
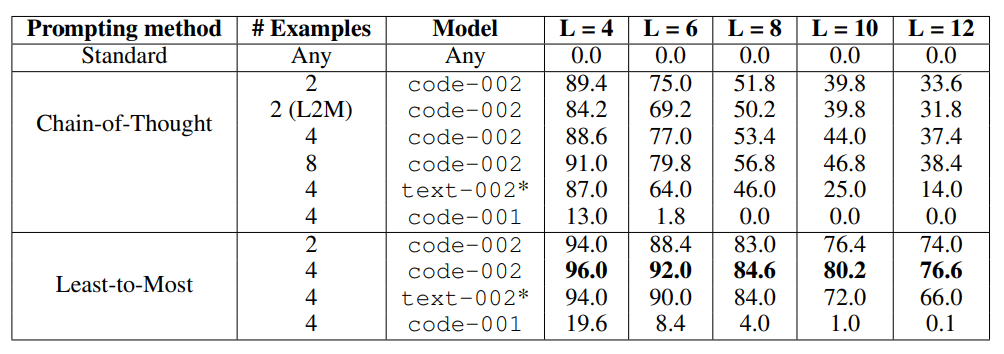
Standard Few-Shot Prompting은 예제 개수를 늘려도 정확도가 0%였다.
CoT는 예제 개수가 많을수록 정확도가 증가하였다.
LTM 또한 예제 개수가 많을수록 정확도가 증가하였고 항상 CoT보다 성능이 우수하였다.
2) Compositional Generalization
SCAN 벤치마크는 compositional generalization을 평가하는 대표적인 벤치마크로 어떤 명령이 주어졌을 때 어떤 action을 취해야하는지 정답으로 변환하는 태스크이다. 기존 seq2seq 모델들은 SCAN의 Length Split에서 성능이 매우 낮다. 훈련 데이터는 짧은 데이터를 사용하지만 test 데이터는 훨씬 더 긴 데이터를 사용하기 때문이다. 따라서 이를 해결하기 위해 neural-symbolic 모델들에 20,000개 이상의 훈련 데이터를 학습시켰다. 하지만 LLM과 L2M prompting을 사용하면 단 몇 개의 예제만으로 SCAN 문제를 해결할 수 있다.

Least-to-Most prompting
1. Decomposition
긴 명령어를 짧은 명령어 목록으로 나누는 방법을 보여주는 예제를 넣어준다.
2. Subproblem Solving
짧은 명령어를 행동 시퀀스로 변환하는 방법을 보여주는 예제를 넣어준다.

python notation을 이용해서 프롬프트 길이를 줄였다.

Chain-of-Thought prompting
L2M과 똑같이 파이썬 표현식을 이용한 프롬프트를 사용했다. 다만 decomposition 프롬프트는 없다.
Results

마찬가지로 L2M이 더 좋은 성능을 보인다.
3) Math Reasoning
GSM8K 및 DROP 데이터셋으로 실험을 진행하였다. L2M이 프롬프트에서 제공된 예제보다 더 어려운 문제를 해결할 수 있는지 평가하기 위해 진행한다.

이전 실험들에서는 문제 분해와 하위 문제 해결을 별도로 수행하였지만 더 단순한 L2M prompting으로도 일반화 성능을 평가하기 위해서 이번 실험에서는 한 번의 프롬프팅으로 두 단계를 모두 포함하는 방식을 사용하였다.
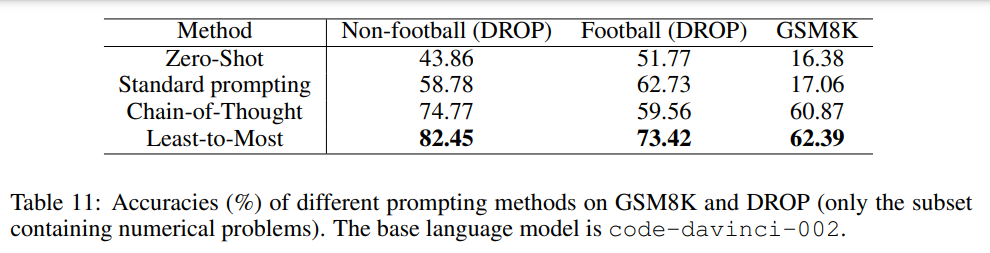

전체적인 정확도에는 별 차이가 없으나 복잡한 문제의 정확도는 L2M이 더 높았다.
Limitation
1. 하나의 도메인에서 학습한 문제 분해 방식이 다른 도메인에서는 잘 작동하지 않는다.
예를 들어 수학 문제의 분해 방식을 배운 LLM이 일반 상식 문제를 적절히 분해하는 데에는 실패한다. 따라서 도메인이 다르면 새로운 분해 프롬프트가 필요하다.
2. 같은 도메인에서도 일반적인 분해 전략이 항상 잘 적용되는 것은 아니다.
하지만 복잡한 문제를 올바르게 분해하는 순간 모델은 정답을 쉽게 찾을 수 있다.
Conclusion
프롬프트가 더 어려운 문제를 해결할 수 있도록 언어 모델을 도울 수 있다.
L2M은 기존의 방법론보다 훨씬 더 우수한 성능을 기록하였다.