* 12.18 업데이트
해당 게시물은 한양대학교 컴퓨터소프트웨어학부 김상욱 교수님 데이터베이스시스템 온라인 강의를 듣고 정리한 자료입니다.
오류가 있다면 언제든 알려주세요!
● 해당 강의의 목표
1. Transaction과 concurrency control(동시성 제어)에 대해 배운다.
▪ Transactions
▪ Concurrency control
▪ Serializability
◆ Transactions
◆ 사용자 또는 application에 의해서 수행되는 데이터베이스 content에 접근하고 바꾸는 action들의 series이다.
예를 들어, 은행의 db에 A, B의 data가 있다. 계좌이체는 A에서 10000을 빼서 B로 10000을 집어 넣는 행위이고 이것이 하나의 transaction이다. db를 access하고 change하는 action이 있다.
◆ db에 가해지는 work의 logical unit이다. 뺀 것을 반영하고 더한 것을 반영하는 이 일련의 과정이 하나의 단위로서 의미가 있다.
◆ db가 가지고 있는 상태들을 database가 consistent state에 있다고 한다. 원래 가지고 있었던 상태도 consistent state이고 만원 이체를 완료한 후의 상태도 또 다른 consistent state에 있다고 한다. 따라서 consistent state에서 다른 consistent state로 database status를 바꿔주는 그러한 연산을 transaction이라고 한다. 다만, transaction이 수행되는 동안에는 consistency가 깨질 수 있다. 예를 들면, A에서 만원을 뺐는데 아직 B에서 만원이 입금이 안 될 수 있다. 이렇게 transaction이 단계적으로 수행하는 과정에서는 consistency가 깨질 수 있다. -> 이를 해소해주는 것이 concurrency control이다.
◆ transaction 결과는 두 가지가 있다.
▪ 성공: transaction이 commit이 되면 database는 새로운 consistent state가 된다.
- 한 번 commit이 되면 그 이후에 취소되면 안 된다. 계좌이체 후 집에 갔는데 갑자기 취소되어버리면 안 된다. 성공된 결과는 DBMS가 보장해야한다.
▪ 실패: transaction이 중단되면 database는 반드시 원래 있었던 과거의 consistent state로 돌아가도록 해줘야한다.
- transaction이 rollback, undone 된다.
◆ Properties of Transaction
Transaction이 가져야하는 4가지 중요한 특징
◆ ACID properties
▪ Atomicity(원자성): transaction의 변경은 atomic하게 이루어져야한다. 돈을 빼서 다른 통장에 더해주는 것은 모두 되거나 모두 안 되어야한다. 수행이 둘 다 되면 새로운 consistent한 state가 되는 것이고 수행이 둘 다 안 되면 전의 consistent state로 돌아가야한다.
▪ Consistency: transaction은 하나의 consistent state로부터 새로운 consistent state로 database를 transform하는 단위이다.
▪ Isolation: 실제로 DBMS 안에서는 하나씩 serial하게 수행되지 않고 여러 개의 transaction이 동시에 수행된다. 이때, 각각의 transaction은 다른 transaction에 의해서 영향을 받지 않아야한다. 다른 transaction의 실패가 타 transaction에게 영향을 미치면 안 된다.
▪ Durability: transaction을 성공적으로 마치면 변경된 효과가 영구적으로 남게 되어야한다. commit 된 후에 failure가 발생해서 commit된 정보를 잃어버리는 일을 허용해서는 안 된다.
◆ DBMS가 위의 네 가지 특성을 transaction이 보장하도록 해야한다. DBMS안에 concurrency control, recovery라는 모듈이 ACID property를 유지할 수 있도록 보장해준다.
◆ Concurrency control
◆ 기본적으로 DBMS 안에 여러 transaction이 동시에 돌아가고 있다. 동시에 돌아가는 transaction들이 서로 방해하지 않도록, isolation이 가능하도록 manage해주는 process를 concurrency control한다고 한다.
◆ ACID property 중에서 isolation에 초점을 맞춘 기능이다.
◆ 왜 concurrency control이 필요할까?
▪ 2개 이상의 transaction들이 db를 동시에 access하면서 적어도 하나가 update하고 있을 때 문제 발생을 예방하기 위해서이다.
▪ 서로 다른 각각의 transaction은 올바르지만 그 transaction의 action(operation)이 interleave되는 상황에서는 잘못된 결과를 초래할 수 있다.
▪ concurrency에 의해 발생할 수 있는 문제점
- Lost update problem
- Uncommitted dependency problem
- Inconsistent analysis problem
◆ Lost Update Problem
◆ 성공적으로 update가 되었는데 다른 transaction에 의해 update한 것을 잃는 것이다.
▪ T1은 100$가 들어있는 bal_x 계좌에서 10$를 빼는 transaction이다.
▪ T2는 100$가 들어있는 bal_x 계좌에 100$를 넣는 transaction이다.
▪ Serial(하나가 다 수행되면 다음이 수행된다.)하게 수행된다고 할 때 최종적으로 190$가 있을 것이다.
Concurrent, interleaved(하나가 수행될 때 다른 것이 같이 수행된다.)
◆ 아래의 그림처럼 동시에 실행된다고 하자. T2의 update가 없어진 결과를 확인할 수 있다.
T2의 update가 끝날 때까지 T1이 읽어가지 못하도록 제어해야 한다. 같은 것을 update하는 conflict 상황이 발생했을 때는 하나가 끝날 때까지 자신을 수행하지 않고 기다려주어야한다. 이 것이 Loss update를 해결하는 방법이다.

◆ Uncommitted Dependency Problem
◆ 하나의 transaction이 다른 transaction이 commit이 되기 전의 중간 결과를 볼 수 있기 때문에 발생한다.
▪ T3은 100$가 들어있는 bal_x 계좌에서 10$를 빼는 transaction이다.
▪ T4는 100$가 들어있는 bal_x 계좌에 100$를 넣는 transaction이다.
▪ T4가 성공적으로 update를 수행하지 못하고 중단되면 atomic에 의해 원래 상태로 되돌리기 위해 rollback을 수행한다.
▪ T3가 rollback하기 전의 새로운 값을 읽었고 그것을 기반으로 10$ reduction을 수행했기 때문에 190$를 최종적으로 쓰게 된다. 만약 serial하게 차례대로 수행이 됐다면 90$이 쓰였을 것이다.
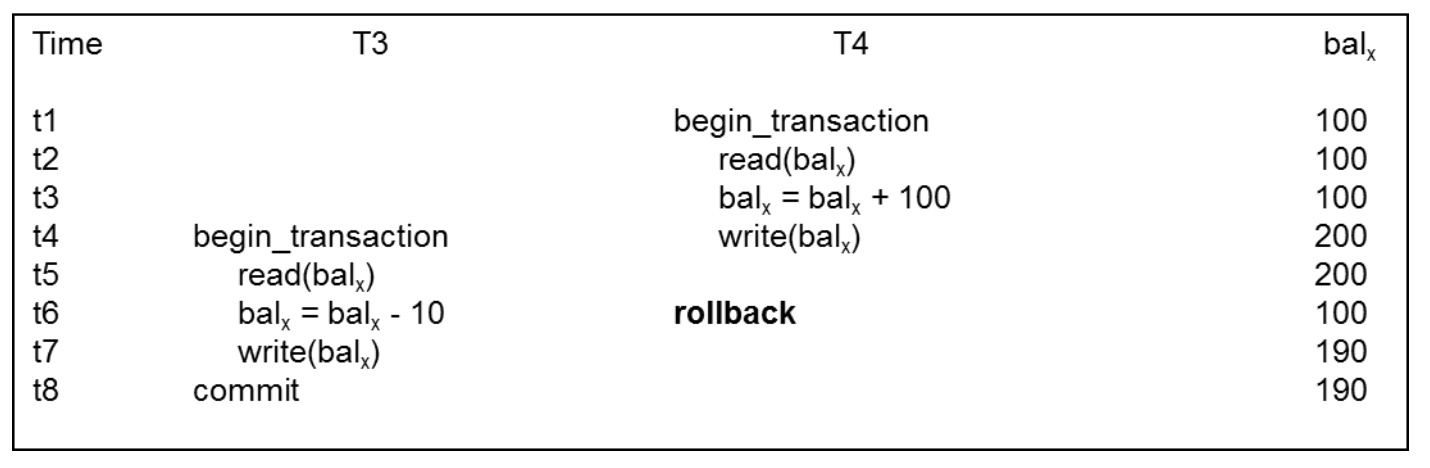
◆ 이 또한 T4가 commit되거나 중단된 후에 T3가 읽을 수 있도록 해야지 이 문제를 막을 수 있다. 두 개의 transaction이 동시에 수행되면서 같은 item을 update하는 상황에서 conflict이 발생할 수 있고 이는 하나의 transaction이 완전하게 마무리된 이후에 다음 transaction이 일어날 수 있게끔 제한하여 해결할 수 있다.
◆ Inconsistent Analysis Problem
◆ 하나의 transaction이 여러 value를 읽고 있는 와중에 다른 transaction이 여러 개의 value 중 일부를 update할 때 발생한다.
◆ 이는 dirty read 혹은 uprepeatable read라고도 부른다.
▪ T5는 bal_x에서 10$를 빼주고 update한 뒤 bal_z에서 10$을 더하고 update한다. T6는 sum에 bal_x를 더하고 bal_y를 더하고 bal_z를 더하고 끝낸다. read only transaction이다.

◆ 2개 이상의 transaction이 같은 item을 다루면서 update가 발생하기 때문에 T5가 update를 마치고 T6가 bal_x, bal_z를 읽을 수 있도록 해야한다.
Q. 그러면 concurrent하게 수행 못하는 거 아닌가요?
A. YES! conflict가 발생하면 concurrent하게 수행하지 않는다. 발생하지 않으면 같이 수행할 수 있다. 읽기만 하면 conflict 아니기 때문에 상관없다.
◆ Serializability
◆ concurrency control의 목적은 서로 다른 transaction들 간의 상호간섭이 일어나지 않도록 transaction들을 순서화하는 것이다.
◆ transaction을 serial하게 하면 동시에 실행하는 것을 허용하지 않는 것이기 때문에 처리 성능이 떨어진다. 전체를 처리하는데 드는 시간이 길어진다.
◆ Schedule: 동시에 수행되는 transaction안의 disk에서 읽거나 쓰는 action들의 순서
◆ Serial Schedule: 하나의 transaction에 속한 opeation이 다른 transaction의 operation의 간섭을 받지 않고 연속적으로 수행되는 것이다. 간섭을 못한다.
▪ serial schedule의 결과가 모두 동일한 것은 아니다. 다만, 모든 serial schedule은 결과가 옳다고 전제된다.
◆ Nonserial Schedule: 동시에 수행하고자하는 여러 개의 transaction안에 들어있는 operation이 섞여있는 schedule이다.
◆ serial schedule과 결과가 같은 nonserial schedule을 찾는 것이 serializability의 목적이다. 이러한 schedule을 serializable이라고 부른다. 이는 concurrent하게 수행되기 때문에 전체적으로 빠르게 수행된다. 다만 일관성이 깨지는 문제가 생길 수 있으니 transaction이 서로 간섭을 받지 않도록 하면서 concurrent하게 수행되도록 해야한다.
◆ 직관적으로 보면, s1, s2 schedule의 결과를 같게 하는 조건
▪ s2에 있는 모든 read와 s1의 read와 같은 value를 읽는다. 대응되는 read가 같은 값을 읽는다.
▪ s1과 s2에 대해서 db에 마지막으로 쓰는 값들은 모두 같다. db에 최종적으로 쓰는 값이 같은 값이다.
◆ Example

T7: x에서 y로 50$를 이체한다.
T8: x에서 10%를 빼고 y에 더한다.
같은 transaction 집합으로 만들어지는 serial schedule이지만 결과가 identical하지 않을 수 있다.
순서가 달라져도 결과가 달라질 수 있다. 틀린 것이 아니다! 어떤 serial schedule의 결과도 모두 옳다!
◆ Serializable schedule s3는 s1과 결과가 같다.
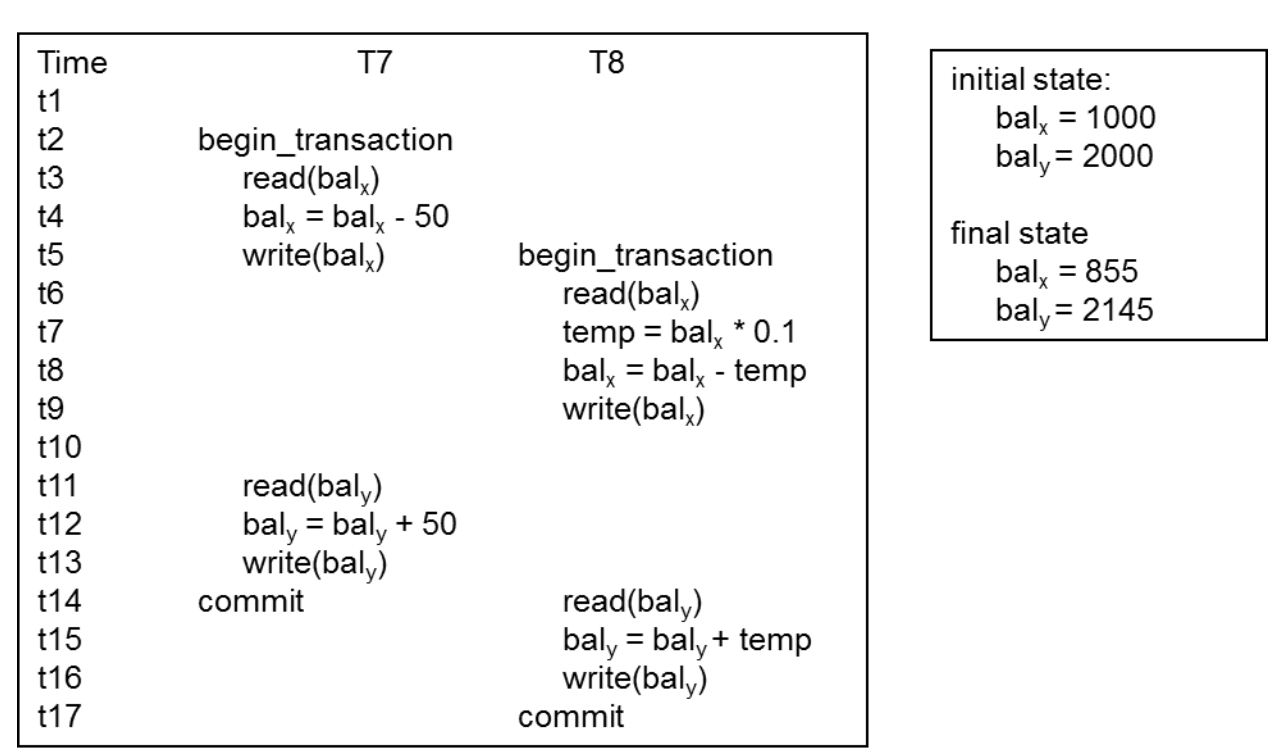
▪ nonserial schedule이 serial schedule과 같은 결과를 내고 있다. 해당 schedule을 serializable schedule하다고 부른다. 사실상 여기서는 결과만 같다는 것이지 아직 equivalent하다고 증명하지는 않았다. 추후 증명해 볼 예정!
◆ nonserializable schedule s4는 s1과 s2 중 어느 것과도 결과가 같지 않다.

▪ serial schedule 어떤 것과도 결과가 같지 않다. 따라서 nonserializable schedule이다.
◆ Transaction 안에 들어 있는 operation read/write의 순서가 중요하다.
▪ 두 개의 transaction이 있을 때 완전히 다른 data item에 대해서 read, write를 한다면 conflict가 없고 순서는 중요하지 않다. 이럴 때는 자유롭게 concurrent하게 수행하면 된다.
▪ 만약 두 transaction이 같은 data item을 read만 한다면 conflict가 없고 순서는 중요하지 않다.
▪ 하나의 transaction이 어떤 data item에 대해 write를 하고 다른 transaction이 같은 data item을 read, write한다면 순서가 중요하다. serial 하게 해야한다.
◆ 제한적인 write rule 하에 serializability를 판단하기 위해서 precedence graph를 사용한다.
write rule: transaction이 어떤 item을 old value를 기반으로 update할 때, 항상 먼저 old value를 읽은 후에 write해야한다.
◆ Precedence graph (주어진 transaction이 있으면 각각의 transaction이 node로 표현된다. 그 안에 transaction id가 들어있다.)
▪ Ti -> Tj인 arc가 있다면 이는 equivalent한 serial schedule에서 Ti가 Tj 앞에 수행되어야한다는 의미이다.
- nonserial schedule에서 Ti가 x item을 read한 후 Tj가 write(x) 했으면 동일한 serial schedule에서는 Ti가 먼저 나오고 Tj가 나중에 나와야한다.
- Ti가 write(x)를 하고 Tj가 read(x) 했으면 serial schedule 상에서는 Ti가 먼저 나오고 Tj가 나중에 나와야한다.
▪ nonserial schedule에 대해서 graph를 그렸을 때 precedence graph 상에서 cycle이 없다면 그 nonserial schedule은 serializable schedule이다.
▪ Examples

◆ Concurrency Control Techniques
◆ concurrent하게 수행되는 transaction operation이 있을 때 serializable한 schedule로 수행할 수 있도록 control하는 메커니즘이다.
◆ 종류
▪ Two-phase locking protocol (이거 중심으로 배운다.)
▪ Timestamp ordering technique
▪ Optimistic technique
◆ Locking
◆ serializability를 보장하기 위해서 가장 널리 사용되는 방법이다.
◆ transaction이 database로부터 item을 읽기 전에 read or write lock을 건다.
▪ Read lock을 걸면 다른 transaction이 그 item을 변경하지 못한다.
- write만 막는 것이다. 같은 item에 대해서 여러 명이 동시에 read lock을 걸 수 있어서 다수의 transaction이 동시에 같은 item에 대해서 read lock를 걸 수 있다.
- shared lock 이라고도 부른다.
▪ write lock은 다른 transaction이 그 item에 read lock, write lock을 걸지 못하게 해서 read, write를 모두 못하게 한다.
- write lock은 item이 단 하나의 transaction을 통해서만 접근할 수 있도록 한다.
- exclusive lock이라고도 부른다.
◆ Lock compatibility matrix
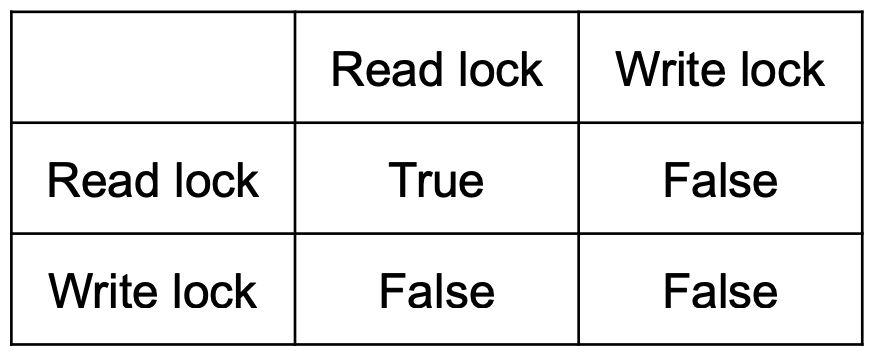
▪ Read lock인 상태에서 다른 transaction의 read lock 허용, write lock 금지
▪ Write lock인 상태에서 다른 transaction의 read lcok 금지, write lock 금지
◆ Lock을 걸기 위한 기본적인 rule
▪ 만약 transaction이 어떤 item에 대해 read lock을 가지고 있다면 그 item을 read만 할 수 있고 update은 못한다.
▪ 만약 transaction이 어떤 item에 대해 write lock을 가지고 있다면 그 item을 read, write 둘 다 할 수 있다.
◆ 어떤 system에서는 transaction이 read lock을 가지고 있다가 write lock으로 level을 올리는 것을 허용한다.
◆ Incorrect Locking Schedule
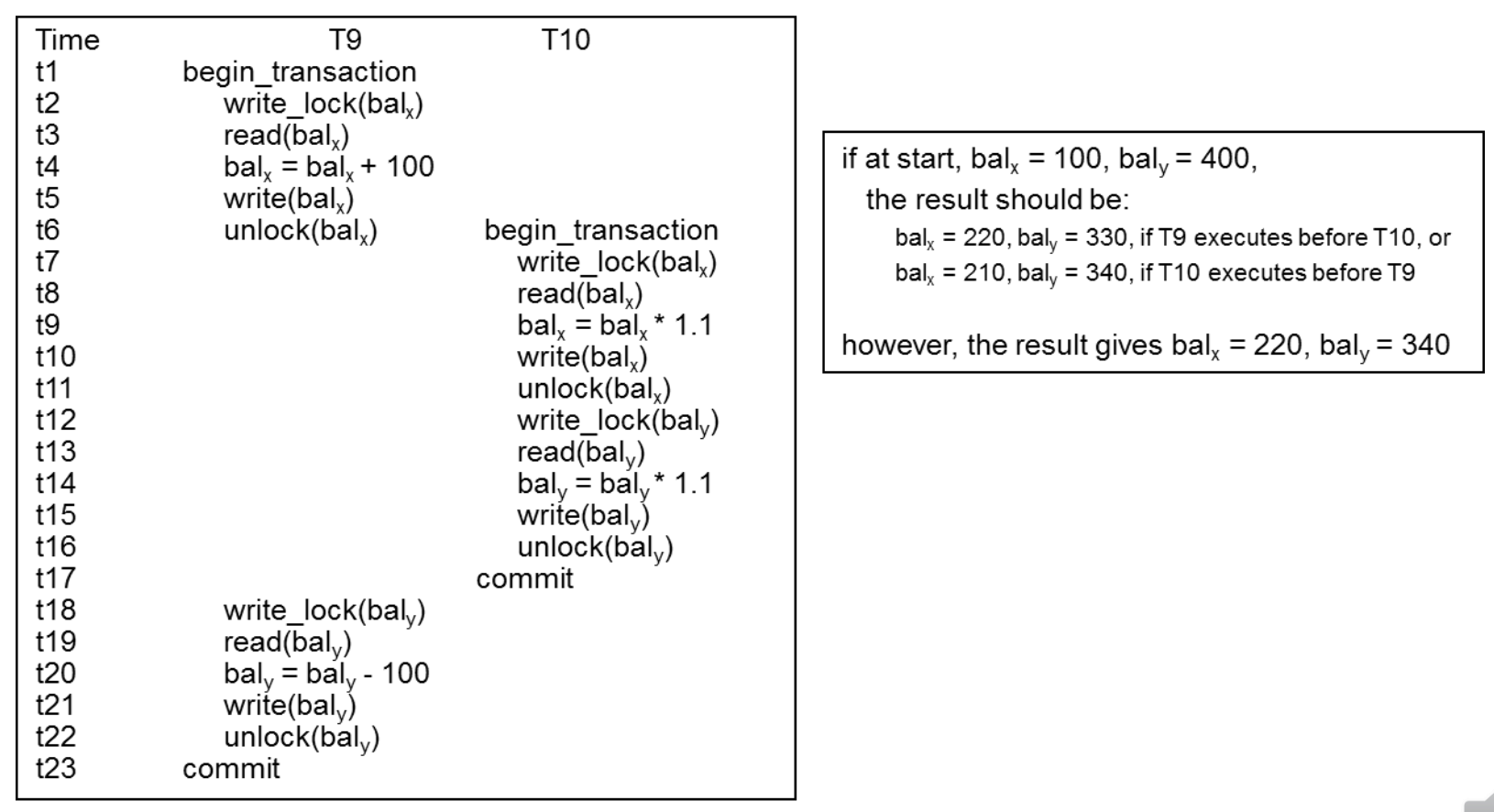
◆ T9: y에서 x로 100$ 계좌이체하려고 한다.
T10: 10%씩 증가시키려고한다.
이러한 nonserial schedule로 실행하면 결과가 serial schedule과 다른다. 규칙을 따라서 했는데 왜!?!
lock을 hold하고 있는 것이 중요하다.
◆ 문제는 transaction들이 lock을 너무 이르게 release해서 뒤에 있는 operation이 lock이 풀려있는 값을 바로 access해서 문제가 발생했다. 따라서 sesrializability를 보장하기 위해서는 lock 여부 외에도 언제 풀지에 대한 기준이 필요하다.
◆ Two-Phase Locking(2PL) Protocol
◆ transaction이 lock을 잡기 위해서는 2단계가 필요하다.
▪ Growing phase: 해당 단계에서는 lock을 잡기만 해야한다.
▪ Shrinking phase: 해당 단계에서는 lock을 풀기만해야한다. 풀기 시작하면 더 이상 lock을 잡는 걸 허용하지 않는다.
◆ 한 transaction이 2PL protocol을 따른다면 모든 locking operation은 모든 unlock operation 앞에 있다. 당연한 얘기! 하나의 transaction 내에서만 적용되는 것이다. 다른 transaction이 unlock을 한 후 lock을 가져가는 것은 2PL 규칙 위반이 아니다.
◆ transaction들이 2PL을 따르면 어떠한 schedule도 serializable이다.
◆ 2PL protocol을 따르지 않는 serializable schedule도 물론 있다. 2PL protocol을 따르는 schedule은 serializable schedule의 일부이다.
◆ Preventing Losk Update Problem Using 2PL

t3에서 lock을 못잡아서 WAIT! unlock 후 T1이 읽고 쓸 수 있다. 이는 자연스럽게 serial schedule과 같은 schedule이 만들어졌다.


2PL을 했더니 serial schedule처럼 동작한다.
◆ Cascading Rollback

◆ 2PL protocol을 잘 지켰다. 근데 T12 T13가 아직 안 끝났는데 T11에서 rollback이 일어나면 T12, T13은 취소를 해야만 한다. 이를 연쇄적인 rollback이라고 한다.
▪ 2PL protocol을 모두 잘 따른다.
▪ T11이 rollback되면 T12가 T11에 dependent하기 때문에 T12가 roll back된다. 마찬가지로 T13도 T12에 dependent하기 때문에 같이 rollback되어야한다.
◆ Strict 2PL protocol
▪ transaction이 끝날 때까지 기다렸다가 모든 lock을 한번에 푼다.
◆ Deadlock
◆ 2개의 transaction이 lock을 잡고 있다. 각각이 다른 transaction이 lock을 내려놓기만을 기다리는 상황이다. 풀릴 가능성이 없다.

◆ DBMS의 converenge control하는 부분에서 transaction들의 상태를 둘러보고 deadlock을 감지하면 둘 중 하나를 kill한다. 그러면 abort, rollback이 되고 작업이 진행된다.
◆ Deadlock Detection and Recovery
◆ DBMS는 deadlock 자체를 막지는 않지만 detect하고 break한다.
◆ 주기적으로 transaction들의 기다리는 상황을 wait-for graph(WFG)를 통해 다룬다.
▪ WFG는 다음과 같이 구성된다.
- 각각의 transaction들이 node가 된다.
- Ti가 Tj의 lock을 기다리고 있을 때 Ti -> Tj로 표현한다.
▪ 만약 WFG에서 cycle이 존재한다면 deadlock이 있다는 것이다.
▪ WFG는 일정 시간마다 계속 생성된다.
◆ Summary
1. Transaction (ACID property)
2. Concurrency control concepts
3. Previous approaches
- 2PL protocol
- Timestamp ordering technique
- Optimistic technique
'3-2 > 데이터베이스시스템' 카테고리의 다른 글
| [DB16] Query Processing, Query Optimization (1) | 2024.12.16 |
|---|---|
| [DB14] Relation Decomposition과 Algorithms (8) | 2024.11.28 |
| [DB13] Normal Form과 Normalization (4) | 2024.11.21 |
| [DB12] Relation Schema를 평가하는 Guideline, Functional Dependency (0) | 2024.11.20 |
| [DB10] INSERT, DELETE, UPDATE SQL 파헤치기 (1) | 2024.11.12 |