Abstract
인공지능 언어 모델이 여러 문제를 해결하는데 널리 사용되고 있지만 여전히 단어를 왼쪽에서 오른쪽으로 순차적으로 예측하는 방식인 Left-To-Right, Token-Level decision Process에 국한된다. 이는 탐험, 전략 예측 혹은 initial decision이 큰 영향을 미치는 문제에 대해서는 어려움을 겪을 수 있다.
Token-Level Decision Process: 이 모델은 문장을 한꺼번에 생성하는 것이 아니라, 단어(또는 서브워드) 단위로 하나씩 생성하며 예측합니다. 즉, 한 번에 문장을 전체적으로 조망하는 것이 아니라 앞선 단어들을 기반으로 점진적으로 단어를 선택합니다.
이를 해결하기 위해서 LM 추론을 위한 새 framework인 Tree of Thoughts(ToT)를 제안하였다. 이는 CoT를 일반화하고 여러 다른 reasoning path들을 고려해서 정교한 decision making을 가능하게 한다.
논문에서는 3개의 새로운 task에 대해 실험을 진행하는데 Game of 24, Creating Writing, Mini Crosswords가 있다. GPT-4 with CoT는 이에 대해 4% 정도의 성능을 보였지만 ToT는 이를 74%로 끌어올렸다.
Introduction
텍스트를 생성하기 위해 기존에 디자인된 모델들은 GPT와 PaLM과 같이 언어 모델의 확장된 버전들이다. 물론 더 다양한 작업을 수행할 수 있는 능력을 보이고 있지만 근본적으로 auto-regressive 메커니즘 형태를 가지고 있다. 이 방식은 left-to-right 방식으로 하나하나씩 token-level decision을 만들어가는 방식이다. 하지만 이러한 간단한 메커니즘이 일반적인 문제를 해결할 수 있기에 충분할지는 의문이다. 이 방식의 한계는 무엇이고 어떻게 해결해야할까?
인간의 사고 방식을 먼저 생각해보도록 하자.
Dual Process Theory에 따르면 사람들은 두 가지 방식으로 결정을 내린다.
1. System 1: 빠르고 자동적으로 무의식적으로 판단한다.
ex) 친구 얼굴을 보고 누구인지 바로 알아차린다. 자동차를 운전할 때 반사적으로 브레이크를 밟는다.
2. System 2: 천천히, 신중하게, 의식적으로 판단한다.
ex) 수학 문제를 풀 때 머릿속으로 여러 단계를 거쳐 답을 구한다. 중요한 결정을 내리기 전에 여러 가능성을 고민한다.
현재의 언어 모델은 System 1과 비슷하게 단어를 하나씩 예측하며 빠르게 결정을 내리는 방식으로 작동한다. 하지만 언어 모델도 사람처럼 System 2의 계획적인 사고를 활용한다면 더 강력해질 수 있다. 따라서 다음과 같은 접근이 필요하다.
1. 여러 가능성을 동시에 고려해야한다.
2. 현재 상태를 평가하고 미래를 내다보거나 되돌아가면서 더 나은 결정을 내려야한다.
이러한 방식이 적용된다면 언어 모델은 더 깊이 사고하고 전략적으로 문제를 해결하는 도구로 발전할 수 있다.
Tree of Thoughts(ToT) framework
기존 언어 모델 기반 문제 해결 방식에는 두 가지 큰 한계점이 있다.
1. 한가지 해결 방법만 따른다.
단순히 한 방향으로만 답을 예측하며, 여러 가지 해결책을 동시에 탐색하지 않는다.
즉, 나무의 여러 branches를 고려하지 않고 한 갈래만 따라간다.
2. 전략적 사고 부족
기존 모델은 미래를 내다보거나 필요하면 되돌아가면서 더 나은 경로를 찾는 방식이 부족하다. 인간의 문제 해결처럼 heuristic 기반 탐색을 적용하여 최적의 해결책을 찾는 과정이 없다.
따라서 이를 해결하기 위해 ToT를 도입한다.
여러 가지 추론 경로를 동시에 탐색할 수 있는 방법으로 언어 모델이 문제 해결을 트리 구조로 프레임화하여 탐색할 수 있도록 한다.
각 노드: 현재까지의 부분적인 해결책
각 브랜치: 다음 해결책으로 나아가는 여러 가지 선택지
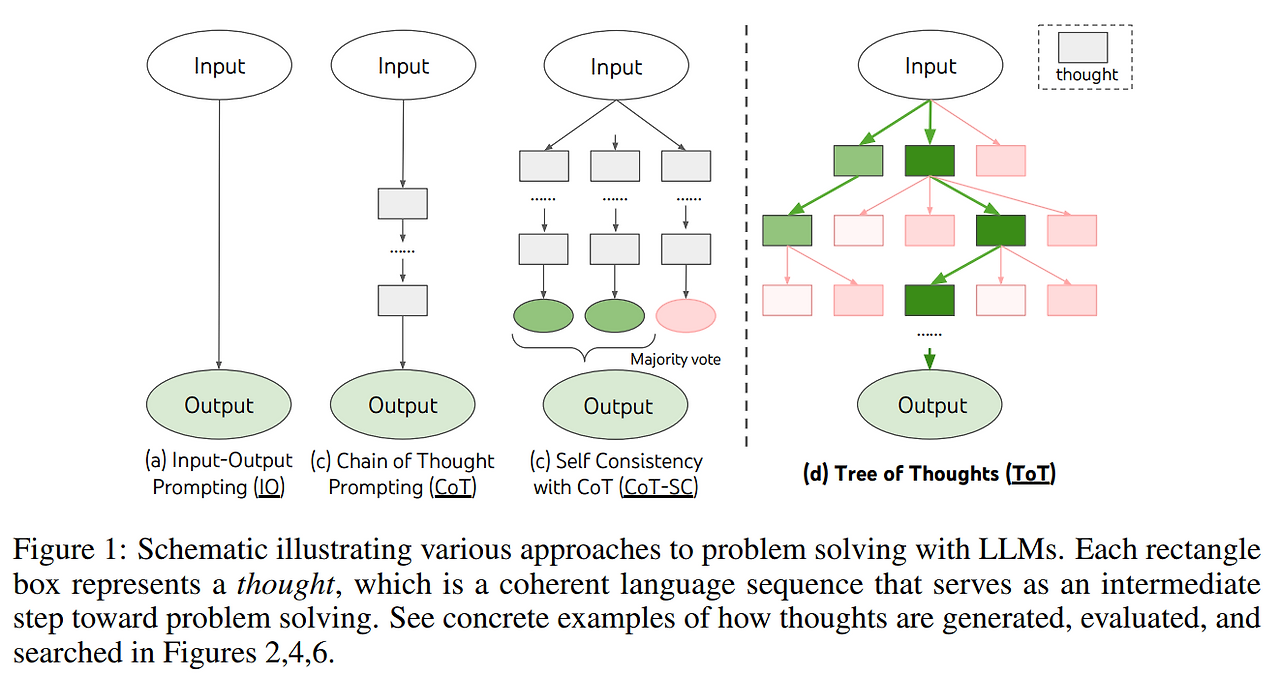
ToT는 Thoughts를 트리 형태로 유지하면서 다양한 경로를 탐색한다. 여기서 Thought는 문맥적으로 의미가 있는 문장 단위로 구성된 중간 단계를 의미한다.
즉, 기존 모델이 단순히 다음 단어 예측 방식으로 문제를 해결하는 것과 달리 ToT는 다양한 해결 방법을 동시에 탐색하고 각 해결책이 문제 해결에 얼마나 기여하는지 스스로 평가할 수 있다.
1. 생각을 트리 형태로 유지
- 문제 해결 과정에서 여러 개의 대안을 동시에 탐색함
2. 스스로 평가 & 전략적 사고
- 각 해결책이 문제 해결에 얼마나 기여하는지 스스로 평가하고 가장 적절한 경로를 선택
- 필요하면 backtracking하거나 lookahead 하는 전략을 사용
3. Search Algorithm과 결합
- BFS(여러 가지 해결 방법을 동시에 탐색), DFS(한 가지 해결 방법을 깊이 탐색한 후 필요하면 되돌아감) 사용
ToT를 만들기 위해서는 다음 4가지 질문에 답해야한다.
- How to decompose the intermediate process into thought steps
- How to generate potential thoughts from each state
- How to heuristically evaluate states
- What search algorithm to use.
1. Thought decomposition
CoT 방식은 생각을 그냥 한 번에 자연스럽게 이어가도록 생성하지만 ToT 방식은 문제의 특성에 맞게 생각의 단위를 설계하고 분할한다.
a thought could be a couple of words (Crosswords), a line of equation (Game of 24), or a whole paragraph of writing plan (Creative Writing)
thought의 사이즈는 너무 작아도 안되고 너무 커도 안된다.
2. Thought generator
현재 상태에서 다음 thought를 어떻게 생성할 것인지 정해야한다.
- 독립적인 생각 여러 개 생성하기
thought 하나가 비교적 길고 풍부한 정보를 담고 있을 때 ex) 창의적 글쓰기: 문단 단위로 여러 개의 아이디어 생성
- 순차적으로 생각 여러 개 제안하기
프롬프트를 사용해 순차적으로 다음 생각을 생성
thought 하나가 작고 명확한 정보를 담고 있을 때 ex) Game of 24(수학 연산 게임), Crosswords(십자말풀이): 한 줄의 수식 또는 한 단어 생성
3. State evaluator
여러 해결 방법 중에 어떤 해결책이 더 유망한지 평가하는 과정이다.
기존의 AI의 상태 평가 방식은 다음과 같았다.
1) Programmed Rules (DeepBlue)
인간이 직접 규칙을 정해 이 상태가 좋은지 나쁜지 평가하였다. 하지만 이는 새로운 문제에 적용하기 어렵다.
2) Learned Models (AlphaGo)
머신러닝으로 학습하여 좋은 상태/나쁜 상태를 구별하도록 훈련한다. 하지만 많은 양의 데이터를 요구하고 비용이 크다.
따라서 ToT는 LM이 스스로 추론하여 상태를 평가하도록 하였다. 두 가지 방식으로 상태를 평가한다.
1) 각각의 상태를 개별적으로 평가하기
각 상태를 독립적으로 평가하여 1~10점 사이의 점수를 매기거나 확실함/가능함/불가능함 등으로 classification한다.
ex)
Game of 24 (연산 게임)
숫자 5, 5, 14가 있으면"5 + 5 + 14 = 24 가능!"→ 좋은 상태
숫자 1, 2, 3이 있으면"24 만들기 불가능!"→ 나쁜 상태
Crosswords (십자말풀이)
"hot l" → "hot e l" (가능한 단어: "hotel")
"tzxc" → 가능한 단어 없음
2) 여러 상태를 비교하여 투표하기
여러 개의 상태를 비교해서 가장 유망한 것을 선택한다. 이는 상태를 개별적으로 평가하기 어려울 때 사용한다.
ex)
Creative Writing (창의적 글쓰기)
"이 문장이 더 자연스러워 보이나요?"
여러 개의 문장을 비교한 후, 가장 적절한 문장에 투표
일반적인 문제 해결
"어떤 해결책이 가장 설득력 있는가?"
여러 개의 해결책을 비교하고 가장 유망한 것을 선택
그리고 이를 더 신뢰성있게 하기 위해서 여러 번 평가하여 평균을 내는 방식을 사용하였다.
4. Search
어떤 경로를 따라 탐색할지 결정하는 방식
1) BFS
여러 가지 해결 방법을 한 번에 고려하여 초기 단계에서 가능성이 낮은 해결책을 제거한다. 트리의 깊이가 얕을 때 유용하다.
현재까지 가장 유망한 b개를 유지하고 예를 들어 최대 5개의 해결책을 유지하며 탐색을 진행한다.
2) DFS
가장 유망한 state를 먼저 끝까지 탐색하는 방법으로 해결책이 불가능하면 탐색을 중단하고 backtracking한다. state evaluator를 통해 더 파고들지 판단한다.
문제 해결 과정에서 깊이 있는 탐색이 필요한 경우 사용하고 가장 유망한 해결책을 먼저 탐색하기 때문에 탐색 범위를 줄이고 계산량을 최적화할 수 있다.
Experiments
ToT 방식의 효율성을 평가하기 위해 실험을 진행하였다. 기존의 최신 언어 모델인 GPT-4를 사용하여 문제를 해결하는데 기존 방법(IO prompting, CoT prompting)과 비교하여 ToT방식이 더 나은 성과를 보이는지 확인한다.

1. Game of 24
주어진 4개의 숫자와 사칙연산을 사용하여 24를 만드는 수학문제
- Task Setup
- 데이터셋
- 4nums.com에서 1362개의 문제 수집
- 난도가 높은 문제 (901~1000번) 중 일부를 테스트에 사용
- 성공 기준
- 정확한 식을 만들어야함.
- 주어진 숫자 4개를 정확히 한 번씩 사용해야함
- 결과가 24가 되어야함
- 평가 방법
- 100개의 문제를 풀어 성공률 측정
- Baselines
- IO prompting
- 기본 프롬프트를 사용하여 답 생성
- CoT prompting
- 3단계의 중간 계산 과정을 포함하여 문제를 해결하도록 설정
ToT에 맞추기 위해 thought를 각각이 중간 방정식인 3개의 step으로 분해했다.
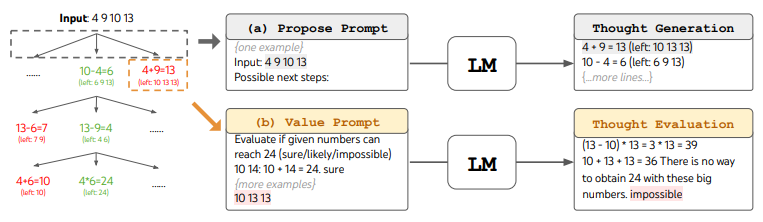
Propose prompt를 사용해 다음에 수행할 수 있는 계산을 생성한다.
Value prompt를 사용해 가능성을 평가하고 불가능한 계산을 제거한다.
가장 유망한 경로를 따라가면서 BFS를 수행하여 해결책을 도출한다.

ToT(b=5)는 74% 성공률로, 기존 방식보다 월등히 높은 성능을 보임
2. Creative Writing
4개 랜덤 문장을 입력받아서 4개의 문단을 만드는 task이다. 다만, 각 문단의 마지막 문장이 입력된 4개 문장과 일치해야한다.
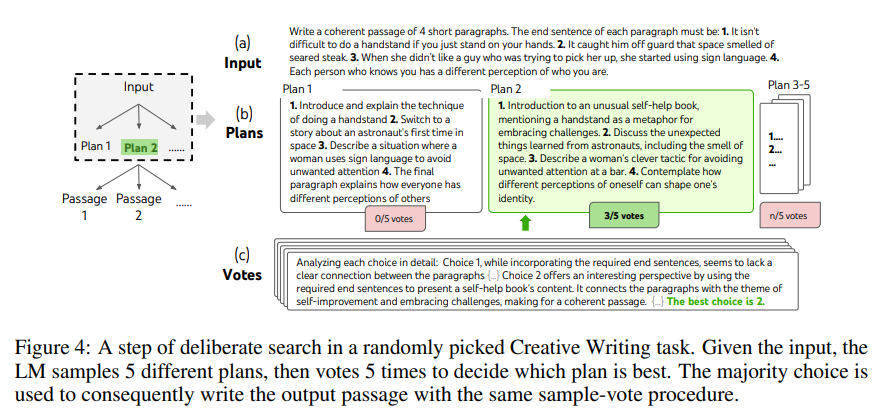
1. 입력이 주어진다. GPT-4는 이 입력을 기반으로 어떤 글을 써야할지 계획한다.
2. GPT-4가 5개의 서로 다른 plan을 생성한다. 각 plan은 글의 전체 구조를 포함한다.
3. GPT-4가 voting을 진행하여 최적의 plan을 선택한다. 다수결로 가장 좋은 plan을 선택한다.
4. 최종 선택된 plan을 기반으로 글을 작성한다.
GPT-4가 글을 처음부터 한 번에 생성하는 것이 아니라 논리적인 구조를 먼저 짜고 난 후에 글을 작성하기 때문에 ToT방식을 따르는 것이다.
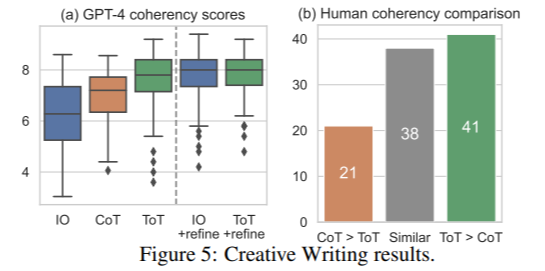
ToT방식이 기존의 방식보다 더 높은 점수를 기록하였다. refine과정을 추가하면 일관성이 더 향상됨을 알 수 있다.
사람들이 어느 쪽이 더 논리적인 글인지 평가를 했을 때 ToT가 더 일관성이 높다고 형가한 사람들이 더 많았다. 따라서 ToT는 단순히 GPT-4 점수뿐만 아니라 실제 사람 평가에서도 더 좋은 결과를 보였다.
3. Crosswords
기존의 수학 문제와 창의적 글쓰기는 비교적 단순한 탐색 문제이다. 따라서 훨씬 더 어려운 탐색 문제를 진행하기 위해 mini crossword 실험을 진행하였다.
데이터
GooBix에서 crossword puzzle data를 가져왔다.
156개 퍼즐 중 20개를 테스트용으로 선정하였다.
가로, 세로 각각 5개씩의 단서가 주어지고 최종 output은 5*5=25개의 글자로 이루어진다.
DFS를 적용하여 일단 가볼 수 있는 곳까지 가보고 막히면 다시 parent node로 backtrack해서 실험을 진행한다.
각 state마다 지금까지 나온 단어들과 proposal prompt를 활용해서 5번 물어봐서 다음 단어를 생성한다.
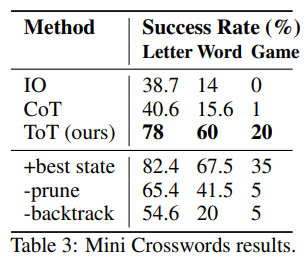
- +best state: DFS 할 때, 휴리스틱하게 ordering 하는게 아니라 진짜 최고 좋은 order로 search 할 경우
- -prune: imposibble state에 대해 prune 하지 않음
- -backtrack: backtracking하지 않고 greedy하게 가장 좋은 단어들로 채우기
Limitations
ToT는 이미 GPT-4가 충분히 좋은 성능을 보여주는 task에서 별로 필요하지 않다.
따라서 이번 논문은 기존 LM이 겪던 3가지 task에 대해 실험을 진행하였지만 LM이 더 광범위하게 사용될 때 더욱 복잡한 task를 수행할 수 있는 능력이 필요할 것이다.
또한 CoT에 비해서는 Cost가 많이 든다.