https://arxiv.org/pdf/2402.01680
0. Abstract
LLM은 요즘 많이 발전을 해서 혼자서도 다양한 일을 잘 처리할 수 있다. 그래서 이 모델을 하나만 쓰는 것이 아니라 여러 개를 통합적으로 써서 더 복잡한 문제를 해결하려는 시도가 많아지고 있다. 이를 multi agent system이라고 부른다. 해당 논문은 그런 LLM 기반 multi agent system이 지금까지 어떻게 발전했는지, 어떤 문제가 있는지, 그리고 어떤 기술이 사용되는지 등을 정리해서 보여주는 서베이 논문이다. 또한 자주 사용되는 데이터셋이나 벤치마크도 정리해두어 쉽게 접근할 수 있도록 하였다.
1. Introduction
LLM은 최근에 사람과 비슷한 수준의 추론 및 계획 수립 능력을 보여주며 remarkable potential을 보여주고 있다. 이는 주변 환경을 인식하고 결정을 내리고 이에 따라 행동하는 autonomous agent에 대한 인간의 기대와 일치한다.
따라서 LLM 기반 agent는 인간처럼 명령을 이해하고 생성할 수 있도록 연구되고 빠르게 발전하고 있으며 다양한 상황에서 정교한 상호작용과 의사결정이 가능해지고 있다. 해당 논문은 이러한 LLM 기반 agent의 발전을 체계적으로 요약하고 있으며 흐름을 확인할 수 있다.
단일 LLM 기반 agent의 성능을 바탕으로 여러 agent의 집단 지능을 활용하기 위한 LLM 기반 multi agent system이 제안되었다. 1) 각기 다른 능력을 가진 다양한 전문 agent로 LLM을 특화시킨다. 2) 여러 autonomous agent가 협력적으로 계획을 세우고 토론하고 의사결정을 수행하도록 한다. 다양한 작업을 해결하기 위해 LLM 기반 multi agent를 활용한 소프트웨어 개발, 다중 로봇 시스템 등 좋은 결과들이 나왔다.
여러 학술 분야에 도움이 되기 때문에 연구가 활발히 진행되고 있으며 아래의 표에서 볼 수 있듯 LLM 기반 multi agent 연구의 영향력이 확장되고 있다. 하지만 그동안 연구들이 개별적으로 진행되었고 이들을 모두 정리하거나 blueprint를 제시하고 future research challenges를 살펴볼 체계적인 review가 부족했다. 따라서 이 논문을 통해 LLM-based multi-agent syatem에 대한 survey paper가 작성되었다.

2. Background
2.1 Singel-Agent Systems Powered By LLMs
LLM-based single agent system의 주요 능력을 시작으로 배경 설명을 한다.
LLM 하나만으로도 agent처럼 작동할 수 있는 3가지 주요 능력이 있다.
1) Decision-making Thought (의사결정 사고 능력)
LLM은 복잡한 문제를 작게 쪼개서 하나씩 해결해나갈 수 있다.
여러 방법을 시도하고 과거의 경험을 토대로 학습을 진행해 문제를 스스로 판단하고 해결하는 능력이 뛰어나다.
2) Tool-use (도구 사용 능력)
LLM은 외부 도구인 API, 계산기 등을 사용할 수 있기 때문에 혼자서 할 수 없는 일도 도구를 통해 많은 작업을 수행할 수 있다.
3) Memory (기억 능력)
LLM은 지금 대화의 맥락을 기억하거나 외부 DB에 정보를 저장하거나 불러올 수 있는 능력이 있다. 따라서 일관된 상호작용이 가능하고 배우는 능력이 좋다.
2.2 Single-Agent VS. Multi-Agent Systems
Single Agent: 똑똑한 LLM 하나를 가지고 스스로 환경과 상호작용하며 작업을 수행한다. 주로 하나의 사고 체계, 하나의 행동 흐름으로 움직인다.
Multi-Agent: 여러 LLM을 각각 특화된 역할로 설정하고 이들 사이에 소통과 협업을 유도한다.
3 Dissecting LLM-MA Systems
LLM multi agent system이 실제로 어떻게 구성되어 있는지를 분석한다. 여러 LLM agent가 팀처럼 협업하는 방식은 마치 사람들이 모여 팀플을 하는 구조와 비슷하다. 이 시스템이 실제로 어떻게 작동하고 환경과 어떻게 연결되며 어떤 방식으로 공동 목표를 향해 나아가는지 설명하기 위해 아래의 일반적인 아키텍처를 제시하고 크게 4가지 요소로 나눠서 살펴보았다.
1) Agents-Environment Interface - 에이전트가 어떻게 외부 환경과 상호작용하는가
2) Agent Profiling - 각 에이전트는 어떤 역할, 성격, 능력을 갖고 있는가
3) Agent Communication - 에이전트들끼리는 어떻게 말하고 정보를 주고받는가
4) Agent Capability Acquisition - 에이전트는 어떻게 배우고 성장하는가
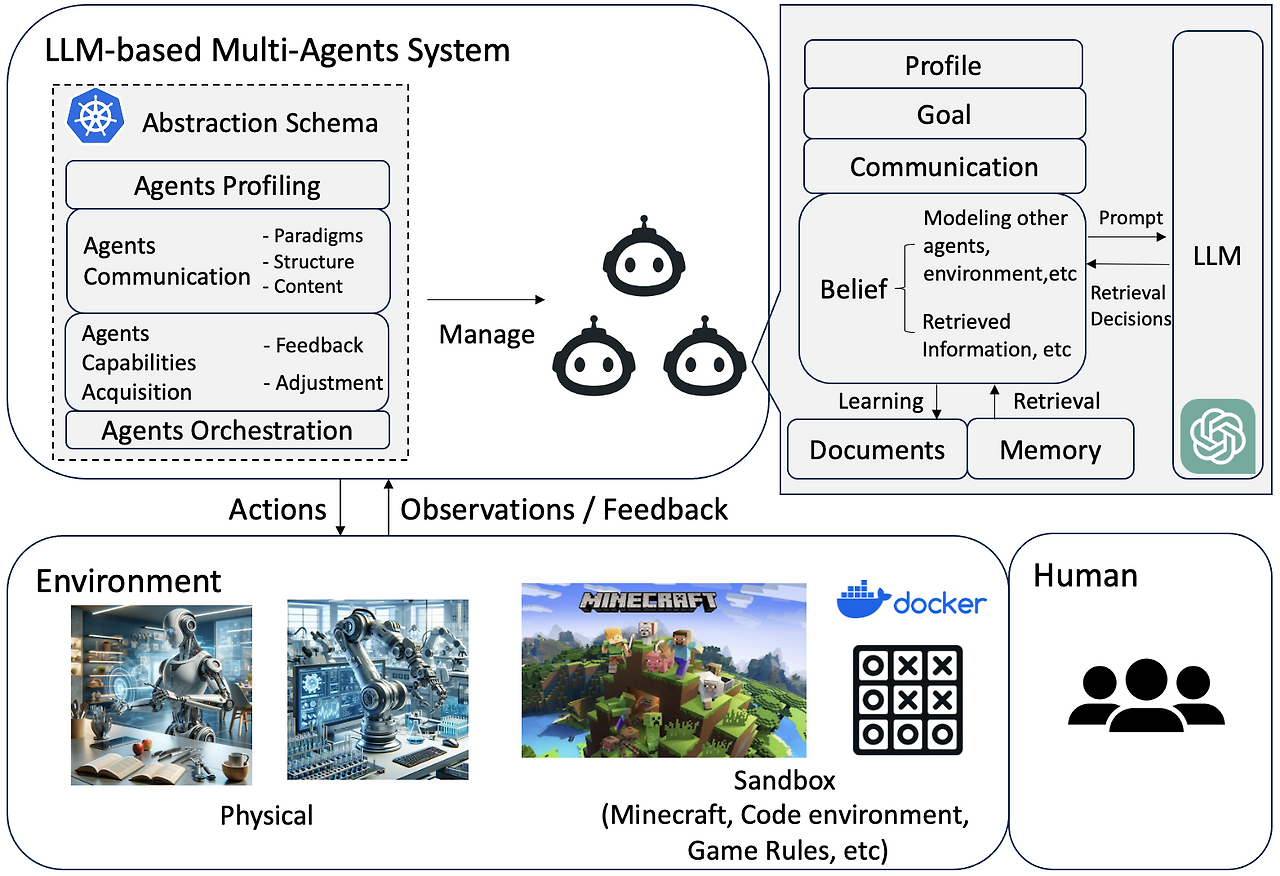
3.1 Agents-Environment Interface - 에이전트가 어떻게 외부 환경과 상호작용하는가
Agent가 활동하는 환경이란 LLM들이 작동하는 상황, 맥락, 공간을 의미한다. 이 환경 안에서 행동을 하고 피드백을 받으며 전략을 조정해 나간다.
예를 들어 Werewolf Game simulation 마피아 게임을 한다고 하자.
환경: 주간/야간의 전환, 토론 시간, 투표 규칙 등
행동: 늑대인간, 예언자 등 각 agent들은 자신의 역할에 따라 행동한다.
조정: 환경으로부터 피드백을 받고 이를 통해 전략을 조정한다.
Agent-Environment Interface는 에이전트가 환경과 상호작용하고 환경을 인식하는 방식을 의미한다. Agent는 이 interface를 통해 주변을 이해하고 결정을 내리고 자신의 행동 결과를 통해 학습한다.
Interface 유형
1) Sandbox
사람이 만든 가상 환경
agent가 자유롭게 행동, 전략 실험 가능
2) Physical
현실 세계와 직접 연결된 환경
로봇이 실제 물건을 조작해 바닥 청소, 샌드위치 만들기
3) None
에이전트들끼리만 대화하고 외부 환경은 없음
어떤 주제에 대해 찬반 토론하며 합의 도출하기
Agent-Environment Interface
에이전트(LLM)가 세상을 인식하고 행동하고 피드백을 받는 통로이다.
Agent = 사람,
Environment = 세상,
Interface = 감각기관 + 팔/다리 같은 도구들
우리가 눈, 귀, 손발을 통해 세상과 상호작용하듯이
에이전트도 어떤 방식으로든 환경과 연결되어야만 행동하고 학습할 수 있다.
그 환경에 세 가지 종류가 있다.
1. Sandbox: 게임 안 세상 같은 시뮬레이션 공간
이 안에서 agent는 자유롭게 실험할 수 있다. 현실에 영향을 주진 않지만 가상의 룰은 있다. 예들 들어 코드를 실행하는 가상 콘솔이 있다.
2. Physical: 진짜 세상에서 움직이는 환경
로봇처럼 현실 세계에서 직접 행동하는 경우를 말한다. 주변에 물건이 있고 그걸 보고 조작해서 결과를 만들어내야 한다. 실제로 물체를 움직이고 피드백을 받야아한다.
3. None: agent들끼리 말로만 협력하는 구조
외부 세계와는 직접 연결되지 않고 agent들끼리 대화하면서 문제를 해결한다. 예를 들어 질문에 대해 여러 LLM이 의견을 내고 설득하며 합의에 도달하는 방식을 말한다.
3.2 Agents Profiling - 각 에이전트는 어떤 역할, 성격, 능력을 갖고 있는가
Agent Profiling이란 agent에게 역할을 부여하고 캐릭터를 만들어주는 것이다. Agent는 단순한 AI가 아니라 각기 다른 특성과 목적을 가진 존재이다. 각 agent가 무엇을 알고 있고 어떤 식으로 행동하고 무슨 목적을 가지고 있는지를 미리 정해줘야 agent들 간의 협업이나 상호작용이 자연스럽고 효과적으로 이루어질 수 있다.
Profiling을 만드는 방법을 3가지로 분류했다.
1) Pre-defined (사전 정의)
시스템 설계자가 직접 에이전트의 역할을 설정한다.
2) Model-Generated (모델 생성)
LLM이 역할을 자동으로 만들어 낸다.
3) Data-Derived (데이터 기반)
기존 데이터셋을 바탕으로 agent의 profile을 정의한다.
3.3 Agent Communication - 에이전트들끼리는 어떻게 말하고 정보를 주고받는가
LLM multi agent system에서는 혼자 자신의 업무를 수행하는 것이라 여러 agent들끼리 서로 정보를 주고받으며 협력하기 때문에 이러한 communication 구조는 system의 두뇌와 같다. 해당 저자들은 이 항목을 3개의 측면에서 분석한다.
1) Communication Paradigms - agent들이 어떤 방식으로 말하는가
1.1) Cooperative: Agent들이 공동 목표를 가지고 협력한다. 정보를 주고받으며 더 나은 해결책을 함께 만들어내려고 한다.
1.2) Debate: Agent들이 서로 다른 의견을 제시하고 반박한다. 상호 비판과 근거 제시를 통해 더 나은 결론을 도출한다.
1.3) Competitive: 각 Agent가 자신의 목표를 달성하기 위해 경쟁한다. 따라서 다른 agent의 목표와 충돌할 수도 있다.
2) Communication Structure - 어떤 구조로 말이 오가는가
2.1) Layered: 조직도처럼 위-아래의 구조로 이루어져 있어서 각 층에 속한 agent는 주로 같은 층 혹은 인접한 층과 소통한다. 따라서 위에서 명령을 하고 아래에서 실행하는 방식으로 이루어진다.
2.2) Decentralized: 중심없이 모든 agent가 서로 직접 연결되어있다. 보통 AI 캐릭터들이 가상 사회에서 서로 일상적으로 대화하면 사회를 구성하는 가상 사회 시뮬레이션 등에서 사용된다.
2.3) Centralized: 중심 agent가 전체 소통을 관리하고 중재한다. 따라서 다른 agent들은 주로 이 중앙 agent를 통해서만 소통한다.
2.4) Shared Message Pool: Agent들이 공통 메시지 공간에 글을 올리고 자신에게 필요한 것들만 구독해서 소통한다. 슬랙, 디스코드처럼 메시지방에서 필요한 채널만 보는 것과 비슷하다.
3) Communication Content - 무슨 내용을 주고받는가
텍스트 기반으로 대화를 나눈다.
3.4 Agents Capabilities Acquisition - 에이전트는 어떻게 배우고 성장하는가
Agent의 습득 능력은 agent가 어떤 피드백을 통해서 학습하는지, 그 feedback을 바탕으로 스스로를 어떻게 조정해 복잡한 문제를 해결하는지에 따라 달라진다.
Feedback
AI는 자신의 행동이 어떤 결과를 낳았는지 그것을 어떻게 개선할 수 있는지 알기 위해서 feedback 과정을 거친다. 해당 저자들은 피드백 유형을 4가지로 나눠서 정리하였다.
1) Environment: 실제 또는 가상 환경으로부터의 피드백
소프트웨어 개발에서는 코드 실행 결과가 피드백이고 로봇 시스템에서는 환경과 상호작용 결과가 피드백이다.
2) From other agents: 다른 agent의 평가나 대화에서 얻은 피드백
토론, 게임 시뮬레이션에서 비판을 듣고 전략을 수정한다.
3) Human feedback: 인간이 직접 주는 피드백
사람이 정답을 주거나 수정해주는 경우를 말한다.
4) None: 피드백이 없다.
단순 시뮬레이션 결과를 분석만 할 때 에이전트는 학습을 따로 진행하지 않는다.
Agents Adjustment to Complex Problems
Agent는 feedback을 받고 끝나는 게 아니라 자기 자신을 진화시키고 조정하면서 점점 더 복잡한 문제를 해결할 수 있게 된다. 저자들은 이러한 방법은 3가지로 나눠서 정리하였다.
1) Memory: 기억 기반 조정
Agent는 과거의 대화, 행동, 피드백을 저장하고 비슷한 상황에서 이러한 경험을 참고한다.
2) Self-Evolution: 자기 진화
자기 자신을 스스로 바꾸는 것을 의미하며 자율적으로 목표를 바꾸거나 전략을 수정하거나 자신을 다시 훈련한다. 단순 기억이 아니라 스스로를 재설계하는 고급 학습 방식이라고 볼 수 있다.
3) Dynamic Generation: 에이전트 즉석 생성
상황이 변하면 새로운 agent를 시스템이 실시간으로 생성할 수 있다. 기존 agent가 부족할 때 새로운 역할에 맞는 맞춤 agent를 만드는 것이다. Agent를 만들다보면 많은 수의 agent를 관리하는 방법이 큰 challenge이다. 이것을 Orchestration이라고 부르며 여러 agent를 언제, 어떻게, 누가, 무엇을 하게 할지 조정하는 방법이다. 이는 추후 6.4에서 다룬다.
이처럼 agent들은 단순히 feedback을 받는 것이 아니라 기억, 자기 진화, 즉석 생성을 통해 점점 더 복잡한 문제에 적응하고 똑똑해진다.
다만, 모든 기능이 항상 모든 agent에게 적용되는 것은 아니고 목표와 환경, 시스템의 복잡도에 따라
조합해서 사용하게 된다.
LLM-MA 시스템은 사람이 어떤 목적을 가지고 어떤 구조로 만들지 정한 뒤에 그에 맞는 agent 구성,
커뮤니케이션 방식, 학습 전략을 짠다.
하지만, 최근에서는 일부 설계 과정을 LLM이 스스로 하도록 하는 실험도 진행 중이다.
시스템의 일부를 사람이 짜고 나머지는 에이전트 스스로 구성하게 하도록 해서 자율성을 높이는
실험적 연구 방향이다. 예를 들어 AutoGen, MetaGPT 등이 있다.
4. Applications
LLM-MA가 실제로 어떻게 쓰이고 있는지 두 가지로 나눠서 정리하였다.
1) Problem Solving과 2) World Simulation이 있다. 이 두 가지 방향은 매우 다르지만 multi agent system의 강점을 살릴 수 있는 대표적인 방향이다.
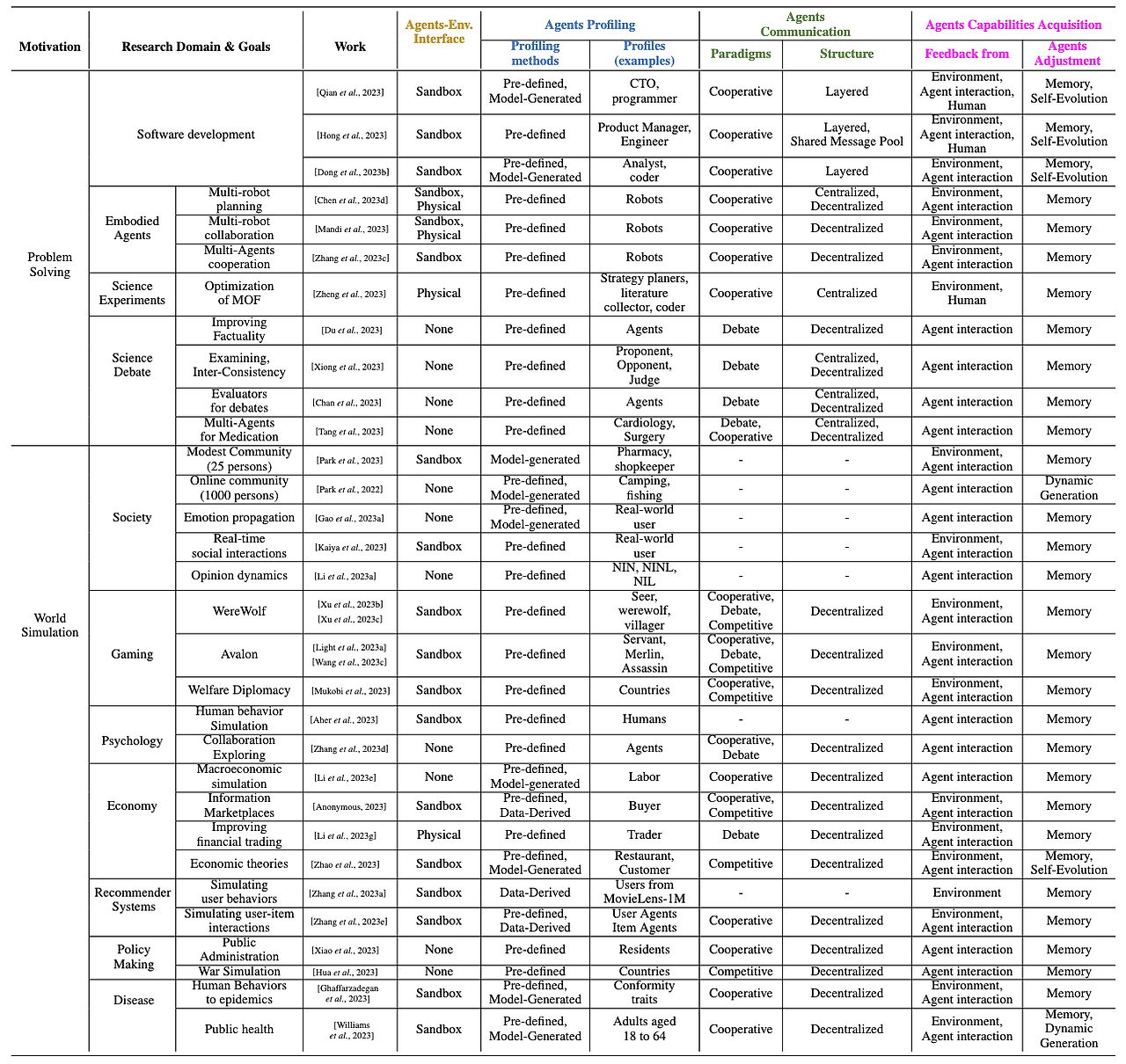
4.1 LLM-MA for Problem Solving
문제 해결을 위한 LLM-MA는 서로 다른 전문성을 가진 agent들이 협력해서 복잡한 문제를 푸는 것을 목표로 한다.
이후로는 어떤 분야들에서 적용될 수 있는지 예시들을 서술하였다. 소프트웨어 개발에서는 기획자, 백엔트, 프로트엔드, QA로 역할 분담을 하고 코드에 대한 토론, 리뷰, 수정 등 협력을 수행하여 문제를 해결한다. 다만, 이 분야는 매우 빠르게 발전 중이라 새로운 응용 사례가 계속 발표되고 있어서 최신 정보를 위해 open source repository를 운영 중이라고 한다.
4.2 LLM-MA for World Simulation
Multi-Agent System을 사용해서 가상의 세상을 구성하고 그 안에서 LLM agent들이 사람처럼 역할을 맡아 상호작용하는 시뮬레이션을 만드는 것이다. LLM이 world simulation에 적합한 이유는 role play를 잘하기 때문이다. 따라서 다양한 인물의 생각, 말투, 입장을 흉내내는 데 탁원하다. 그래서 하나의 마을을 만들고 어떤 LLM은 선생님, 어떤 LLM은 시장, 어떤 LLM은 학생 이렇게 프로파일을 주면 사람처럼 대화하고 반응한다. 이를 통해서 가상 사회, 게임, 정책 실험, 경제 모델링에 사용한다.
5. Implementation Tools and Resources
5.1 Multi-Agents Framework
LLM-MA system을 실제로 만들고 싶다면 어떤 framework를 쓰면 좋을지를 설명한다. 가장 대표적인 오픈소스 framework 3가지를 소개한다.
1) MetaGPT: LLM이 마치 회사처럼 움직이도록 만들자. Standard Operation Procedure (SOP)를 코드에 반영해서 현실적인 역할 수행이 가능하게 했다.
human workflow processes를 LLM에 반영하여 hallucination problem을 줄였다. 또한 역할 분리가 잘 되어 있어 현실 업무에 적합하다.
2) CAMEL(Communicative Agent Framework): 에이전트 간의 자율적인 대화 협업 실험
Inception prompting이라는 기법을 사용해서 초기 프롬프트를 잘 설계해서 agent들이 자연스럽게 대화하며 협업할 수 있도록 만들었다. 어떻게 하면 LLM이 서로 의미있게 대화하며 일할 수 있는지를 연구하는 프레임워크이다.
Inception Prompting
단순히 각 agent한테 역할만 부여하는 것이 아니라 self-awareness(자기인식)을 만들어주는 프롬프트 설계방식이다.
ex: 소프트웨어 개발 시나리오 (CAMEL)
1. 프론트엔드 에이전트의 inception prompt
당신은 프론트엔드 개발자입니다.
팀의 목표는 Todo 앱을 개발하는 것입니다.
당신은 UI/UX에 집중하며, 백엔드 개발자와 협력해야 합니다.
당신의 역할: UI 구현, 백엔드와 API 정의 조율
당신의 의사소통 스타일: 정중하고 기술적이며 협력적
2. 백엔드 에이전트의 inception prompt
당신은 백엔드 개발자입니다.
당신은 프론트엔드 개발자와 협력해 서버 로직을 설계하고 구현해야 합니다.
당신은 Python(FastAPI)을 사용할 예정이며, API 명세를 정확히 맞춰야 합니다.
협업을 위해 상대방의 요청을 논리적으로 분석하세요.
이런식으로 각 agent에게 자기 역할, 협업 목표, 소통 스타일까지 각인시키는 것이 inception prompting이다.
3) AutoGen: 가장 유연하고 코딩, 수학, 게임 등 다양한 분야에 적용될 수 있다.
어떤 LLM을 연결할지, 어떻게 행동할지, 누가 누구랑 대화할지 등을 모두 원하는 대로 설정 가능하다.
MetaGPT, AutoGen은 agent를 스스로 구성할 수 있을까?
YES!
두 프레임워크 모두 사람이 최소한의 개입만 하면 agent들이 스스로 구성되고 알아서 일을하게 만들 수
있다.
MetaGPT
사람이 "웹사이트 하나 만들어줘" 같은 단순한 요구를 하면
시스템이 알아서 기획자, 개발자, 디자이너, QA agent들을 구성하고 각자 역할에 맞게 협업 시나리오를
구성한다. SOP 기반으로 "기획자 -> 설계자 -> 개발자 -> QA"의 조립 라인식 업무 플로우가 자동
실행된다. 사람은 그냥 목표만 말하고 맡기면 되는 것이다.
AutoGen
사람이 자연어나 코드로 agent 구조를 한 줄씩만 짜주면 된다.
from autogen import AssistantAgent, UserProxyAgent
pm = UserProxyAgent("Project Manager")
dev = AssistantAgent("Developer", llm_config=...)
pm.initiate_chat(dev, message="간단한 계산기 앱 만들어줘")
이런식으로 짜주면 이후 대화는 LLM들끼리 진행하고 새 agent를 동적으로 생성하거나
작업 실패 시 다시 계획 짜는 것도 자동으로 이루어진다.
5.2 Datasets and Benchmarks
LLM multi agent system이 제대로 작동하는지 평가하기 위해 데이터셋과 벤치마크 기준을 사용한다.
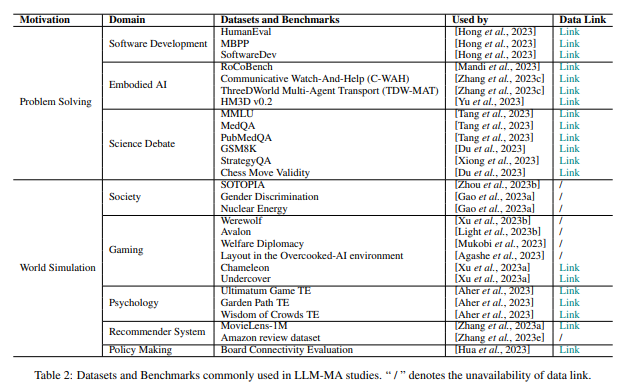
Task-solving 시나리오에서는 여러 LLM 에이전트가 협업, 토론해서 문제를 푸는 능력을 평가하고 world simulation 시나리오에서는 시뮬레이션된 세상이 현실과 얼마나 비슷한가, 에이전트들의 행동이 인간스러운가를 분석한다. 다만 일부 분야는 아직 벤치마크가 부족해서 이를 만드는 것이 중요한 연구 과제라고 말한다.
6. Challenges and Opportunities
6.1 Advancing into Multi-Modal Environment
지금까지 대부분의 LLM-MA 연구는 text 기반인데 실제 세상은 텍스트, 이미지, 음성, 비디오 등 다양한 정보가 섞여있다. 따라서 이제는 text만 처리하던 LLM이 사진도 보고, 소리도 듣고 행동도 이해하고 실제로 움직일 수도 있게 해야하는 것이 목표이다.
6.2 Addressing Hallucination
LLM-MA에서는 이 문제가 더 심각한게 한 agent가 잘못된 정보를 말하면 다른 agent들이 그것을 사실이라고 믿고 기반으로 계획을 세운다. 연쇄적으로 이러한 작용이 계속 일어나면 시스템 전체가 도미노처럼 오류를 확산한다. 따라서 개별 agent의 사실 확인 능력을 강화해야하고 정보 전달 흐름을 조절해서 오류가 퍼지지 않도록 관리해야한다. 네트워크 상에서 오류 전파 방지 알고리즘 또한 필요하다고 말하고 있다.
6.3 Acquiring Collective Intelligence
전통적인 multi agent system은 강화학습 기반으로 학습했기에 사전 dataset으로 훈련했다. 하지만 LLM-MA는 즉각적인 피드백을 기반으로 학습된다. 하지만 이런 interactive한 환경을 설계하는 것이 어렵고 그런 환경이 없으면 학습 자체가 제한되어 확장성이 떨어진다. 또한 대부분의 학습 방식은 각각의 agent만 따로 똑똑해져서 집단 최적화가 없다. 따라서 여러 agent들을 동시에 상호작용 기반으로 조정해서 집단 지능을 만드는 것이 아직 주요한 과제로 남아있다.
6.4 Scaling Up LLM-MA Systems
GPT-4 같은 LLM 하나만도 비싸고 무거운데 여러 agent 여러개를 돌리면 GPU, 메모리, 연산량이 모두 급증한다. 또한 agent 수가 많아질수록 누가 누구와 말하고 어떤 순서로 일하는지 혼돈이 온다. 이를 해결하기 위해 Agent Orchestration이 필요하다. 이를 잘하면 작업 분담을 최적화 할 수 있고 에이전트 간 중복을 방지하여 충돌 최소화, 통신 비용 절감들이 가능하다. 또한 agent 수가 많아질수록 system이 어떤 방식으로 변할지에 대한 수학적 모델링 연구도 새롭게 진행되고 있다.
6.5 Evaluation and Benchmarks
현재 평가 방식은 너무 좁은 문제, 개별 agent가 얼마나 잘 이해하고 추론하는가만 평가한다. agent끼리의 집단 행동, 복잡한 상호작용은 평가하지 못한다. 또한 많은 분야에 아직 benchmark가 없다. 연구는 존재하지만 비교할 기준이 없는 것이다. 따라서 아직 LLM-MA system이 잘 돌아가는지 객관적으로 비교, 평가하기가 어렵다.
6.6 Applications and Beyond
현재 적용되고 있는 분야를 넘어 금융, 교육, 헬스케어 등 다양한 응용 분야에 적용 가능하고 한문적 이론 기반 연구인 인지 과학, Cybernetics 등으로도 확장될 수 있다. 따라서 단순한 도구가 아니라 탐구하는 이론적 모델로도 사용될 수 있다.
7. Conclusion
LLM 기반 multi agent system은 집단 지능을 가진 강력한 framework이며 이 논문은 그 발전과 구성 요소, 응용 사레, 도전 과제 등을 정리한 survey 논문이다. 해당 논문이 다양한 분야의 연구자들이 LLM-MA를 탐수할 수 있도록 좋은 출발점과 방향성을 제공하길 바란다고 하며 마친다.