Abstract
문제
- 사람과 마찬가지로 LLM도 한 번에 좋은 답을 내지 못할 수도 있음.
제안
- SELF-REFINE 방법을 제안하여 인간처럼 LLM도 자기 피드백으로 글을 다듬게 하자.
- 방법
- 처음에 LLM이 답을 작성
- 그 답을 다시 LLM이 읽고 스스로 피드백을 작성
- 해당 피드백을 반영하여 더 나은 답을 재작성
- iterative refinement
- 장점
- 별도 학습이 필요 없음
- 라벨링 데이터가 필요 없음
- 강화학습없이 단 하나의 LLM만 있으면 됨.
- 실험
- 7개의 과제에서 실험 진행
- 기존 방식보다 평균 20% 성능 향상을 보였고 사람과 자동 평가 모두에서 더 나은 결과로 평가됨.
1 Introduction
문제 상황
- LLM이 일관성 있는 출력을 생성할 수 있지만 여러 목적이 얽혀 있는 과제나 목표를 명확히 정의하기 어려운 과제와 같은 복잡한 요구사항을 다루는 데는 부족한 면이 있음.
- 기존에는 LLM 출력 결과를 다듬기 위해 domain에 특화된 data를 사용해 다른 모델을 따로 학습시키거나 사람이 정답 데이터를 라벨링하거나 보상 모델을 써야함.
- → 비용도 많이 들고 데이터 준비도 어려움.
해결 방안
- 인간처럼 LLM이 스스로 초안 → 피드백 → 개선을 반복하도록 하자.
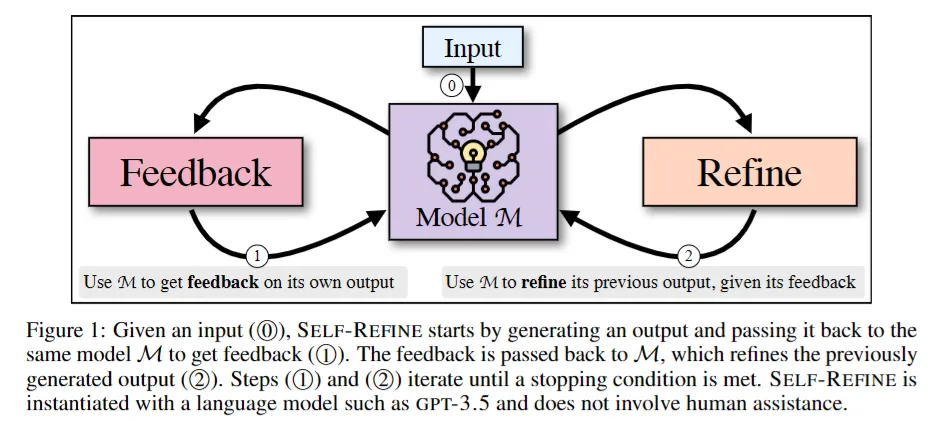
제안: SELF-REFINE
- FEEDBACK과 REFINE 두 과정을 번갈아 수행하는 iterative self-refinement algorithm
- 작동 방식
- 초안 생성
- 같은 모델에게 해당 출력을 피드백용 입력으로 다시 전달하여 초안 수정
- 정해진 반복 횟수 또는 모델이 더 이상 수정이 필요없다고 판단할 때까지 반복
- 모델이 피드백을 생성하고 이를 반영해 수정된 출력을 생성할 수 있도록 few-shot prompting 사용
실험 결과
- 7가지 생성 과제에 대해 평가 진행
- direct generation 방식보다 5~40% 더 높은 성능을 보임
- CODEX와 같은 코드 생성 모델에 SELF-REFINE방법을 적용했을 때 최대 13%의 절대 성능 향상을 얻음.
의의
- LLM이 처음에는 최적 출력을 만들지 못하더라도 피드백을 통해서 개선이 가능하다.
- 하나의 모델만으로 별도의 학습 없이 피드백과 수정을 반복하는 방식으로 더 나은 출력을 얻는 효과적인 방법
2 Iterative Refinement with SELF-REFINE
Initial generation
입력 $x$, 생성 프롬프트 $p_{\text{gen}}$ , 모델 $M$이 주어졌을 때, SELF-REFINE은 다음과 같이 초기 출력 $y_0$를 생성함.
$y_0=M(p_{gen}∥x)$
$p_{gen}$: 해당 과제에 맞춘 few-shot 프롬프트. 입출력 쌍 $⟨x(k), y(k)⟩$포함.
FEEDBACK
동일한 모델을 사용해 이전에 생성한 출력 $y_t$에 대해 피드백 $fb_t$생성
$fb_{t} = M(p_{fb}∥x∥y_t)$
$p_{fb}$: 피드백 생성을 위한 과제 특화 프롬프트. 입력-출력-피드백 3개의 예시로 구성된 few-shot 형태 $⟨x(k), y(k), f b(k)⟩$
Refine
동일한 모델을 사용해 직전 출력 $y_t$를 피드백 $fb_t$에 따라 수정
$y_{t+1} = M (p_{refine}∥x∥y_t∥fb{_t}) .$
$p_{refine}$: $<x^{(k)}, y^{(k)}t , fb_t^{(k)}, y^{(k)}{t+1}>$ 입력, 초기출력, 피드백, 수정된 출력 4개의 요소를 모두 포함한 few-shot 예시로 구성된 프롬프트
Iterating SELF-REFINE
FEEDBACK단계와 REFINE단계를 교대로 반복
정지 조건이 충족될 때까지 반복됨.
$stop(f_{bt}, t)$→ 지정된 반복 횟수 $t$에 도달했을 때 종료 or 피드백 $fb_{t}$ 에서 정지 지표를 추출하여 판단
(모델이 피드백을 생성할 때 정지 여부를 함께 출력하도록 프롬프트를 유도할 수 있음)
$y_{t+1} = M (p_{refine}∥x∥y_0∥f b_0∥...∥y_t∥fb_t)$
실제로 refine은 수정 단계에서 지금까지의 전체 history를 담을 수 있도록 프롬프트를 누적 추가하면서 구성됨.