ACL ARR 2024 December Submission
ICLR 2025
0. Abstract
문제의식
- 기존 LLM-MA 시스템은 한계가 존재함.
- 제한적인 agent 간 협업
- 사전에 정의된 Standard Operating Procedures(SOP)에 의존 → 사람의 개입이 많이 필요함.
제안: MegaAgent
- 단 하나의 프롬프트로 전체 시스템을 작동시킬 수 있는 LLM-MA 프레임워크
- 특징
- 동적 에이전트 생성: 작업의 복잡도에 따라서 자동으로 agent 수 선택됨
- 작업 분해 → 각 그룹이 병렬 실행
- agent의 모니터링 및 관리 기능 포함
- 성능
- Gobang 게임 구현: 800초 내 개발 성공
- 국자 정책 시뮬레이션: 590개의 agent가 다영역 정책을 병렬로 실행
1. Introduction
현황
- LLM의 뛰어난 계획 수립 능력과 인지 능력으로 MAS 발전
- ex) MetaGPT: metaprogramming 도입하여 소프트웨어 개발 과정 시뮬레이션 / Simulacra: 25개의 LLM 에이전트 사회적 상호작용
문제
- MAS의 두 가지 한계
- 확장성과 유연한 조정 실패
- 작업이 크고 복잡할 경우, 수백 개의 에이전트를 생성해 사회 시뮬레이션을 수행할 때 adaptive coordination 하지 못함.
- 사전 정의된 구성에 의존
- 사전에 정의된 각 agent의 역할, SOP, 정적 그래프에 의존
- 확장성과 유연한 조정 실패
해결책
- MegaAgent 설계
- large task → multiple hierarchical subtask
- 각 작업은 특정 agent 그룹이 전담하여 수행
- agent 그룹 내부 혹은 그룹 간 통신 가능
- 사용자는 Boss Agent에게 meta prompt 하나 제공.
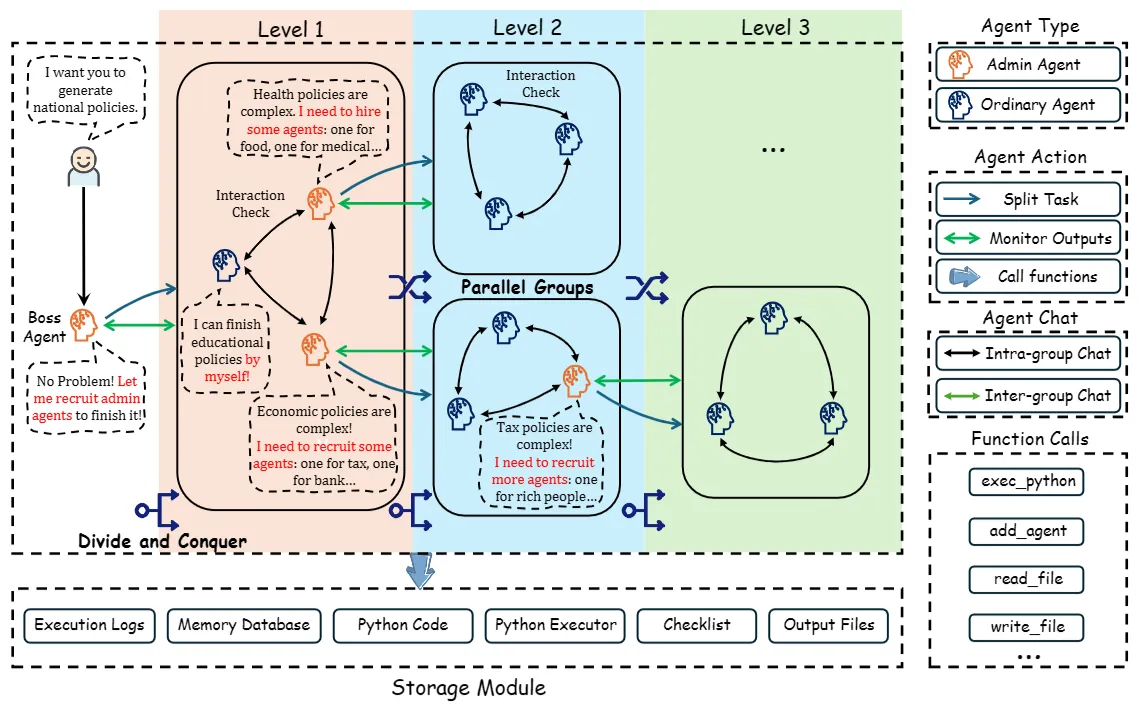
- 사용자가 프롬프트 하나만 주면, Boss Agent가 전체 작업을 자동 분해하고 Admin Agent 고용
- 각 Admin은 필요시 세부 작업을 나누고 Ordinary agent를 생성해서 팀 구성
- Admin Agent 아래 구성된 Ordinary Agent 그룹들이 병렬적으로 작업 수행 시작
- 모든 agent들은 function call을 통해 module에 접근 가능
두 가지 주요 기능
- Hierarchical Task Management
- Boss Agent Level Task Decomposition
- divide task → assign to admin agents
- Dynamic Hierarchical Group Formation
- 하위 작업이 Admin 혼자 처리할 수 없는 경우, 동적으로 추가 agent 모집
- 재귀적으로 구성된 계층형 그룹에 형성되어 복잡한 작업 분산 처리
- System-Level Coordination and Communication
- 병렬 실행과 agent간 상호작용
- function call을 통해 외부 시스템이나 저장소와 연결
- Boss Agent Level Task Decomposition
- Hierarchical Monitoring
- 각 agent는 상위 Admin Agent로부터 작업을 할당 받음.
- Agent-Level Monitoring: 체크리스트 기반으로 자신이 한 작업 추적, 진행 상황 검증
- Group-Level Monitoring: Admin Agent는 자신이 배정한 agent 작업 감독
- System-Level Monitoring: Boss Agent는 모든 그룹의 최종 결과물 확인
- 각 agent는 상위 Admin Agent로부터 작업을 할당 받음.
2. MegaAgent Framework
2.1 Hierachical Task Management
2.1.1 Multi-level Task Splitting
같은 Level에 있는 에이전트 그룹들 간 병렬 처리 메커니즘
2.1.2 Hierarchical Coordination Mechanism
- Intra-group Chat
- 같은 작업 그룹에 속한 agent들끼리는 프롬프트 기반 커뮤니케이션을 통해 상태나 업데이트 공유
- Inter-group Chat
- 서로 다른 그룹의 Admin Agent들끼리 직접 커뮤니케이션하여 작업간 의존성 문제를 해결하고 여러 그룹 간의 협업 조정
- Ordinary Agent는 자신의 그룹 외의 agent와는 직접 통신이 제한
2.1.3 Message Queue Mechanism
각 agent들은 Producer-Consumer 패러다임을 기반으로 한 message queue system을 통해 비동기 통신을 수행함.
- 외부 agent들은 producer로서, 함수 호출을 통해 message 생성
- message를 받은 대상 agent는 consumer로 동작하며 일정 주기마다 message queue를 polling 하여 여러 개의 message를 한꺼번에 가져감.
Agent 작동 상태 종류
- Idle State
- message가 없는 상태. 비활성 상태
- Processing State
- message를 가져오면 LLM 추론을 수행하는 처리 상태로 들어감.
- 받은 message는 다음 처리 상태까지 queue에 남아있음.
- Response State
- 처리된 출력은 validity check을 거친 후 function call을 통해 결과 전송
- queue가 비어있으면 Idle 상태로, message가 남아있으면 processing 상태 다시 진입.
2.1.4 File Management
storage module 도입
file management를 효과적으로 하기 위해 도입한 설계 방식
- Git-Based Version Control
- agent는 파일을 읽을 때 해당 파일의 현재 git commit hash를 가져옴.
- race condition 방지
- Long-Term Memory Management with a Vector Database
- LLM agent는 token 길이 제한으로 인해 몇 round가 지나면 이전 대화를 잊어버리는 문제가 존재
- 이를 위해 각 출력은 언어 모델을 통해 embedding 되어 벡터 형태로 DB에 저장됨.
2.2 Hierarchical Monitoring
MAS내의 오류를 줄이기 위해 oversight, error correction, progress validation 기능을 실시간으로 지원
2.2.1 Multi-level Monitoring
- Agent-Level Monitoring
- 자기 자신만의 checklist 유지
- 자신이 수행한 작업 기록, 진행 상황 검증 용도
- Group-Level Monitoring
- Admin Agent가 자신의 group 감독
- 그룹 내 작업을 조율
- System-Level Monitoring
- 최상위에서 Boss-Agent가 모든 그룹의 결과물 검토
- 결과물이 올바른 형식을 따르고 있는지 hallucination 없는지 확인
2.2.2 Failure Scenarios and Solutions
Monitoring은 Output format Verification, Result Validation에 중점을 둠.
- Output Format Verification
- 일관된 출력 형식을 강제
- Result Validation
- 한 그룹이 작업을 마치면 Admin Agent가 생성된 결과 검토
- 초기 작업 요구사항과 일치하는 비교
- 불일치가 발견되면 오류 메시지를 남기고 관련 agent에게 수정 요청
자주 발생하는 실패 시나리오와 그에 대한 해결 방안
- Incomplete TODO Lists
- 작업을 다 끝내지 못하고 종료 혹은 무한 루프에 빠짐.
- Admin Agent가 이를 감지하고 작업을 다시 retry하도록 지시
- Task Repetition
- context length limitation으로 인해 이미 완료한 작업을 잊고 다시 반복함.
- Admin Agent는 agent의 checklist와 실제 작업 내역을 대조해서 문제를 발견하고 필요한 요청
- Secure Alignment Interruptions
- Agent가 응답을 멈추거나 제한 message만 반복함.
- Admin Agent는 새로운 agent를 추가 고용해서 작업을 이어서 완수
3. Experiments
3.1 RQ1: Standard Benchmarks
3.1.1 Experiment Setup
Benchmark
- MBPP
- HumanEval
- MATH
- GSM-8K
Model
- GPT-4o
3.1.2 Experiment Results and Analysis
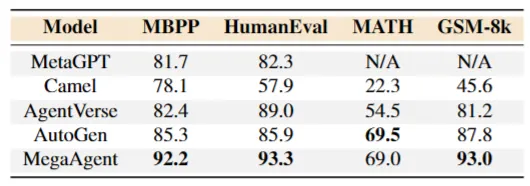
- 추론 능력을 더 많이 요구하는 MATH, GSM-8K에서도 비슷하거나 더 높은 정확도를 기록함.
- 모든 벤치마크에서 일관된 우수한 성능을 보임.
3.2 RQ2: Gobang Game Development
오목을 직접 개발해서 사람과 게임을 진행하는 과제
백엔드 로직, 프론트엔드 UI의 동시 개발 요구
3.2.1 Experiment Setup
Model
- GPT-4o
3.2.2 Experiment Results
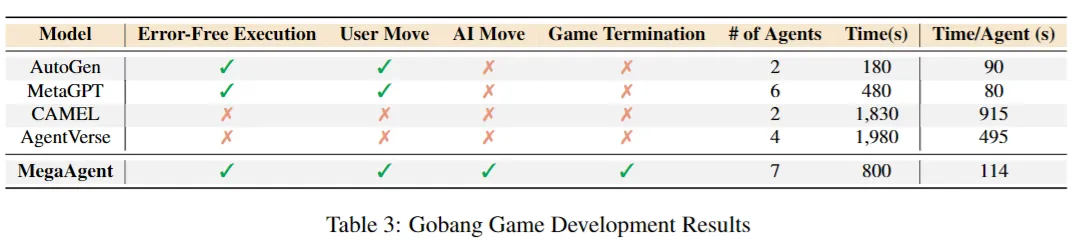
7개의 agent를 포함하는 SOP를 자율적으로 생성하고 UI까지 포함된 게임을 800초 이내에 개발
3.3 RQ3: National Policy Generation
국가 정책 수립 작업
교육, 보건, 금융 등을 포함한 복잡한 분야들에 대해 다양한 작업을 수행할 많은 agent 필요
3.3.1 Experiment Setup
Model
- GPT-4o-mini
3.3.2 Evaluation Metrics
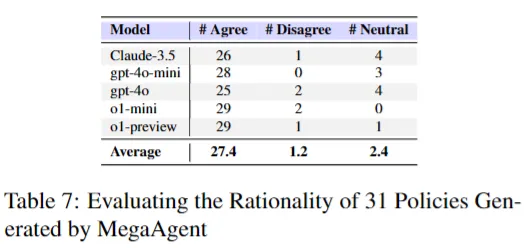
국가 정책의 신뢰성을 평가하기 위해 LLM-as-a-Judge 프레임워크 사용
사용 LLM model
- Claude-3.55
- GPT-4o-mini
- GPT-4o
- o1-mini
- o1-preview
3.3.3 Experiment Results


평가 프롬프트를 사용해 LLM에게 MegaAgent가 생성한 국가 정책의 신뢰성과 타당성 평가 결과
5. Conclusion
- MegaAgent라는 대규모 자율 LLM 기반 멀티에이전트 시스템 소개
- 여러 실험을 통해 자율성과 협업 능력에서 기존 시스템들보다 뛰어남 증명
Limitations
- 계획 수립과 agent간 통신 과정 bottleneck
- agent 수와 통신 round 수가 많아질수록 입출력 token 사용량이 폭증하며 시스템의 효율성과 비용 모두에 영향을 줌.
- Hallucination in Agent Outputs
- checklist로 agent를 감시하지만 여전히 hallucination 발생함.
- 출력 포맷이 요구한 형식에서 벗어나는 경우도 있음.
- API Cost and Model Integration
- GPT-4에 의존하고 있기 때문에 API 사용 비용이 매우 큼.