https://arxiv.org/abs/2305.14325
0. Abstract
배경
- LLM은 생성, 이해, few-shot 학습에서 뛰어난 성과를 보여줌.
- 성능 향상을 위해 여러 prompting 기법들이 사용됨.(verification, self-consistency, scratchpad 등)
제안 방법
- 여러 LLM이 개별 응답과 추론을 제시한 뒤 서로 debate를 하고 최종 합의된 답을 도출하는 구조
효과
- 수학적/전략적 추론 능력 크게 향상
- 허위 정보나 hallucination 감소
- factual validity 향상
적용성
- 블랙박스 모델에도 적용 가능(내부 구조 변경 없이도 사용 가능)
- 모든 태스크에 동일한 프롬프트 절차로 적용 가능 → 범용성 우수
1. Introduction
배경
- LLM은 방대한 텍스트로 학습이 되었지만 그 안의 정보들이 정확하거나 고품질이라는 보장은 없음.
- 따라서 오답을 말하거나 hallucination을 많이 겪음.
- 이를 위해 few-shot / zero-shot CoT prompting, verification, self-consistency, scratchpad과 같은 기법들이 활발히 연구됨.
제안 방법
- Society of Mind 이론과 MAS에서 영감을 받아 여러개의 agent가 각자 답을 제안하고 서로의 응답과 추론을 토론해서 최종 합의된 답을 도출하는 도구 제안
- 질문 제시 → 여러 개의 LLM이 후보 답안 생성 → 각 모델이 다른 모델들의 응답을 모두 읽고 비평 → 피드백을 바탕으로 자신의 답 수정 → 여러 라운드에 걸쳐서 반복 → 답 도출
결과
- 토론을 여러 round 반복하는 것 + 여러 model agent를 사용하는 것이 모두 성능 향상에 도움을 줌.
- 같은 종류의 모델을 여러 개 띄워도 처음엔 각 모델이 다른 답이나 추론을 내놓기도 함.
- but, 토론을 거치면 결국 합의된 답으로 정리됨.
- 모델이 확신하지 못하는 잘못된 정보는 빠질 가능성이 높음.
- 단순히 정답을 확대하는 구조가 아님. 초기에는 모두 틀린 답을 냈지만 토론을 통해 결국 정답에 도달하는 경우가 많음.
장점
- 다른 기법을 대체하는 것이 아니라 독립적이라 결합성이 높음.
- 비용이 많이 들긴 하지만 훨씬 정확도는 높으며 추가적인 훈련 데이터도 생성할 수 있음.
평가
- 실제 인물 전기 정보로 구성된 벤치마크 제작
- LLM도 해당 문제에서 잘못된 답을 내기도 하고 instance마다 다른 답을 내지만 debate를 하면 훨씬 성능이 올라감.
2. Language Generation through Multiagent Debate
2.1. Multiagent Language Generation
Debate 과정
- 질문이 주어지면 동일한 LLM을 사용하는 여러 agent가 각자 답변을 생성함.
- 다른 agent들의 응답을 모두 포함한 consensus prompt 제공
- 각 agent는 이를 바탕으로 새로운 답변 작성
- 다른 agent들의 답을 검토하고 이를 바탕으로 자신의 답을 수정하는 역할 수행
- iterate를 돌며 성능 향상

ex)

2.2. Consensus in Debates
여러 debate 후에 LLM agent들이 하나의 합의된 정답에 도달하도록 보장할 수 있을까?
- 반드시 수렴된다는 보장 없음.
- but, 실험 결과 대부분 하나의 공동된 답에 수렴함.
- 프롬프트를 통해 모델이 자신의 답변에 대한 신뢰도와 debate round수를 조절할 수 있음.
- Figure 3의 프롬프트가 debate 지속 시간에 어떤 영향을 주는지 보여줌.

- 또한, LLM agent들은 agreeable함.
- dabate가 끝났을 때 의견이 나뉘는 경우에는 다수결로 정답을 정함.
3. Experiments
3.1. Improving Reasoning with Multiagent Debate
실험 목적:
multiagent dabate 구조가 LLM의 reasoning을 얼마나 향상시키는가?
Task:
- 산술식을 정확하게 계산할 수 있는지 평가 (가장 간단한 단계. 단순 연산이지만 괄호 없이 순서 계산 필요)
- GSM8K dataset을 활용한 초등 수학 추론 문제 (중간 난이도. 수치 추론 + 텍스트 이해 필요)
- 체스 전략 추론 능력 (첫 14수가 주어졌을 때 그 다음 최적의 수를 예측 PGN 포맷 사용. Stockfish 엔진으로 예측 수의 우위 점수 측정. 가장 어려움.)
Baselines:
- Single-agent 방식
- Self-Reflection 방식: LLM이 먼저 답을 생성하고 그 답에 대해 self-reflect 수행
- 여러 instance로부터 답변을 받고 majority voting
- 여러 self-agent를 ensemble한 방식도 함께 비교 (Appendix)
모델: ChatGPT-3.5 / GPT-4와 LLaMA-7B에 대한 결과도 제공
Quantitative Results:

Qualitative Results:


Compatibility with Other Reasoning Methods:

3.2. Extracting Factual Information from Multiagent Debate
실험 목적:
Multiagent debate 방식이 언어 모델의 factuality를 얼마나 개선하는지 평가
Task:
- Biographies: 역사적 인물의 전기를 정확히 생성하는지 평가
- MMLU: 시험에서 나올만한 지식 문제에 대한 답변의 정확도 평가
- 체스 수 선택 과정에서 hallucination 분석
Baselines:
- 위의 실험과 동일
Results:




질문이 모호하거나 모델이 확신이 없을 때 서로 다른 답을 내놓는 경향이 있지만 ‘이 답에 얼마나 자신있니’라고 물어보면 모두 자신 있다는 답변만 내놓는 문제점이 있음.
but, with debate 빠르게 의견을 바꾸고 더 정확한 정답에 수렴함.

3.3. Analysis: Understanding Multiagent Debate
Multiagent Debate의 성능 향상이 어디서 오는가?
Number of Agents:
Arithmetic 문제에서는 agent수가 많아질수록 성능이 꾸준히 향상됨.
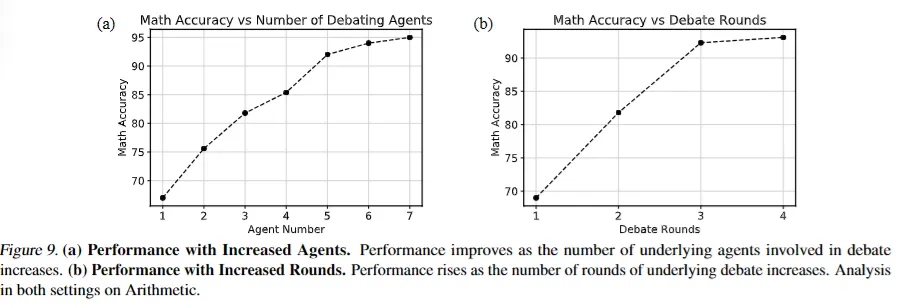
Rounds of Debate:
Arithmetic 문제에서 debate round 수가 많아질수록 성능도 꾸준히 향상됨.
debate round가 증가할수록 confidence 증가, 불확실성 감소.
Effect of Debate Length on Accuracy:
Figure 10에 결과 나와있음.
Using Different Initialization Prompts:
각 agent에게 다른 persona를 부여했더니 MMLU에서 성능이 향상되었고 특화된 agent 구성이 추가적인 성능 향상을 가져올 수 있음을 시사.
Summarization:
지금까지의 실험에서는 각 agent가 다른 agent들의 응답을 모두 이어 붙여 다음 응답을 생성하도록 함.
agent 수가 많아질수록 비용이 급격히 증가함.
→ 다른 agent들의 응답을 먼저 요약한 후, 그 요약본만 다음 agent에게 제공하면 더 효율적인 debate가 가능해짐.

Using Different Language Models:
서로 다른 LLM, chatGPT, Bard에게 GSM8K 수학 문제 20개를 주고 dabate하도록 함.
서로 다른 모델이 협업하면 성능이 더 좋아짐.
- Bard 단독: 11개 정답
- chatGPT 단독: 14개 정답
- 함께 디베이트한 경우: 17개 정답

5. Limitations and Conclusion
Limitations:
- 비용이 많이 듦. → 최종 답변을 원래의 단일 모델로 distill하면 해결됨. 학습만 다수 모델로 하고 실행은 단일 모델이 하도록 경량화 가능
- debate round가 길어질수록 LLM들이 문맥을 제대로 따라가지 못함. → context window size 증가 혹은 이전 응답들을 요약해서 제공
Conclusion:
- 여러 개의 모듈형 language agent가 협력해 문제를 해결하는 방식은 앞으로도 유망할 것.