오랜만에 comeback!!
https://arxiv.org/abs/2506.07982
0. Abstract
현황
- 기존 벤치마크는 AI agent만이 도구를 사용할 수 있는 환경을 가정함.
- 사용자는 수동적인 정보 제공자일 뿐 능동적인 역할을 하지 않음.
- 현실에서는 사용자도 적극적으로 시스템의 상태를 변경해야 할 경우가 많음.
제안: $τ^2$-bench
- Dual-control 환경 (Dec-POMDP 기반): Agent와 user 모두 tool을 사용해서 공유된 동적 환경을 제어함
- Compositional task generator: 다양하고 검증 가능한 과제를 자동으로 생성
- 환경과 밀접하게 연동된 사용자 시뮬레이터: 도구 및 상태에 따라 현실적인 동작만 수행, 시뮬레이션의 현실성 및 신뢰성 향상
- 정교한 agent 성능 분석: agent 성능을 정교하게 분석할 수 있도록 다양한 요소 제거 실험 제공
결과
- 사용자 없이 혼자 행동할 때보다 사용자를 안내하며 행동하는 상황에서 성능이 크게 하락함.
1. Introduction
현황
- 기존의 벤치마크는 AI가 사용자와 소통하고 적절한 행동 순서를 따라 문제를 해결하는 능력을 테스트함.
- 하지만 모두 단일 제어 환경으로 AI만 환경과 상호작용할 수 있는 구조임.
- → 사용자는 단순히 정보 제공자의 역할만 함.
- $τ$-bench와 같은 사용자는 지시문만 보고 환경을 추론해야하며 AI의 행동을 직접적으로 관찰하거나 영향을 줄 수 없음.
- 현실은 ‘휴대폰을 껐다 켜세요’ 등과 같은 실제 행동을 취하는 능동적 행위자임.
제안: $τ^2$-bench
- 현실의 복잡성을 담아내기 위해서 tau2-bench를 제안
- 사용자도 도구를 사용하고 환경을 조작하는 직접적인 행동 가능
- 현실성과 명확성을 증가시키기 위해 제공하는 기능
- 사용자에게 일부 정보만 보여줄 수 있어서 현실적인 제한을 시뮬레이션 가능
- 사용자가 직접 도구를 호출해 대화 외적으로도 환경 조작 가능
- 자연어보다 도구 포맷으로 사용자 행동을 지정하면 더 명확하게 시나리오 구성 가능
Challenge
- user 시뮬레이터에게 도구를 통한 자율성을 부여함과 동시에 agent와 user사이의 complexity asymmetry도 유지해야함.
- 사용자의 기능을 제한하여 여전히 문제 해결에 있어서는 agent의 도움을 필요로 하도록 해야함.
- 해결책
- 사용자 도구는 사람이 읽을 수 있는 출력만 제공
- 사용자가 계획적으로 도구를 사용하는 것을 제한하고 오직 agent의 요청에 반응하는 방식으로만 사용하게함.
- 환경 자체를 통해 사용자 행동을 제약
기여점
- Telecom dual-control domain
- AI agent와 User 모두가 각기 다른 도구를 사용하여 공유되고 동적으로 변하는 환경을 관찰, 조작, 검증 가능
- Dec-POMDP를 이용해 형식화
- SOTA 모델들도 해당 domain에서 상당한 어려움을 겪음. (pass@1 GPT-4.1: 34%, o4-mini: 42%, claude-3.7-sonnet: 49%)
- Compositional Task Generator
- 프로그래밍 방식으로 작동하는 태스크 생성기 포함 → 기본 시나리오들로부터 검증 가능한 다양한 태스크를 자동으로 구성 가능 (기본 시나리오: 시작 상태, 해결 방법, 체크 방법)
- Reliable user simulator
- user 시뮬레이터를 환경에 밀접하게 연동시킴.
- User simulator의 자연어 prompt의 복잡성을 줄여줌.
- Fine-grained diagnosis of agent failures
- agent의 성능을 분해해서 평가 가능
- no-user mode
- agent가 모든 도구를 통제하여 순수한 추론 능력만을 평가
- dual-control mode
- 사용자와의 의사소통 및 협업이 필요한 환경
- agent가 사용자를 지도해야함.
- no-user mode
- 실험 결과, dual-control mode에서 성능이 평균 20%p 하락함.
3. $τ^2$-bench: Evaluating Agents in a Dual-Control Environment
대화형 AI agent와 user simulator간의 multi turn interaction을 체계적으로 연구하기 위한 플랫폼
Decentralized Partially Observable Markov Decision Process (Dec-POMDP)로 모델링되며 해당 구조에서 agent, user모두가 소통하고 도구를 사용하고 관찰함.
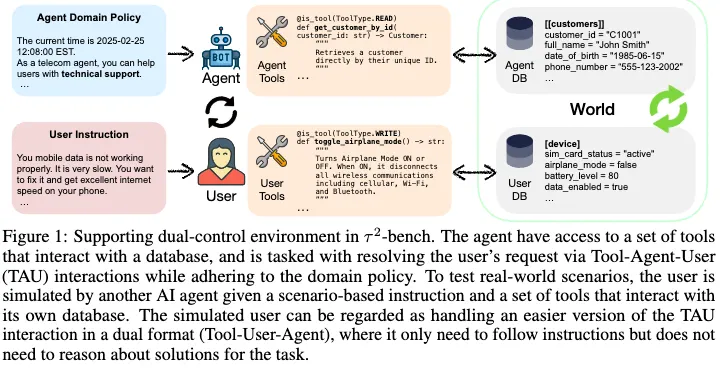
3.1 The Dec-POMDP Formalism
- 전체 process는 다음과 같은 튜플 형식으로 정의
- $(S, {Ai}, {Oi}, T , R, U, M)$ ($i ∈ {agent, user}$)
- Message space $(M)$
- agent와 user 간에 주고받을 수 있는 모든 자연어 메시지 집합
- State space(S)
- Global State: $S = S_{world} ⊗ S_{history}$
- $S_{world} = S_{db,agent} ⊗ S_{db,user}$ agent와 user 내부 DB 상태
- $S_{history}$ 상호작용을 하며 발생한 모든 event들을 기록
- ex) 통신 도메인
- $S_{db,user}$: 휴대폰의 상태(비행기 모드, 네트워크 상태 등)
- $S_{db,agent}$: 고객 정보나 회선 정보가 담긴 CRM 데이터
- Action space($A_i$)
- 도구 호출 ($a_{i,tool} ∈ A_{i,tool}$): 함수 호출로 $S_{db,i}$와 상호작용
- 메시지 전송 ($m_i ∈ M$): 오직 한 명의 player만 행동 가능.
- Observation spaces ($Oᵢ$)
- 플레이어 i의 관찰에는 두 가지 종류가 있음.
- 도구 관찰 ($o_{i,tool}$): 도구 호출 결과(데이터, 메시지, 에러 등)
- 상대방의 메시지 관찰($m_j ∈ M$): 오직 한 명의 player만 관찰 가능
- Transition function $(T)$
- $T: S × A → S × O$
- 현재 상태 $s$와 행동 $a = (a_{agent}, a_{user})$가 주어지면, 새로운 상태 $s’$와 관찰 $o = (o_{agent}, o_{user})$가 반환됨.
- 플레이어 $i$가 도구 $a_{i,tool} ∈ A_{i,tool}$를 호출하면 $S_{world}$가 변경되고 도구 출력 $o_i ∈ O_{i,tool}$가 생김.
- 메시지 $m_i ∈ M$를 보내면 상대방은 $o_j = m_i$로 관찰을 받음.
- c, d 모두 s’는 업데이트된 $S_{world}$와 $S_{history}$를 포함함.
- Reward function $(R)$
- $R : S → [0, 1]$
- 전체 상태 s를 기반으로 태스크 성공 또는 실패 여부를 나타내는 글로벌 보상 값을 제공
- ex) user의 모바일 데이터가 되지 않는 문제가 해결되고 그것이 사용자 DB 상태로 검증되면 에이전트는 보상을 받음.
- Instruction Space $(U)$
- 현실적인 사용자 시뮬레이션을 유도하는 시나리오
- 에이전트가 사용자 지원시 따라야하는 도메인 정책
Global State: $S = S_{world} ⊗ S_{history}$
Global State: $S = S_{world} ⊗ S_{history}$
- 이러한 Dec-POMDP 형식은 복잡하고 상호작용적인 시나리오를 시뮬레이션하는데 이점 제공
- 사용자가 agent의 안내를 받아 도구를 실행하는 협업 환경을 현실적으로 시뮬레이션할 수 있도록 함.
- 사용자는 더 예측 가능한 행동을 하게 되고, 자연어 프롬프트에 대한 의존도 감소
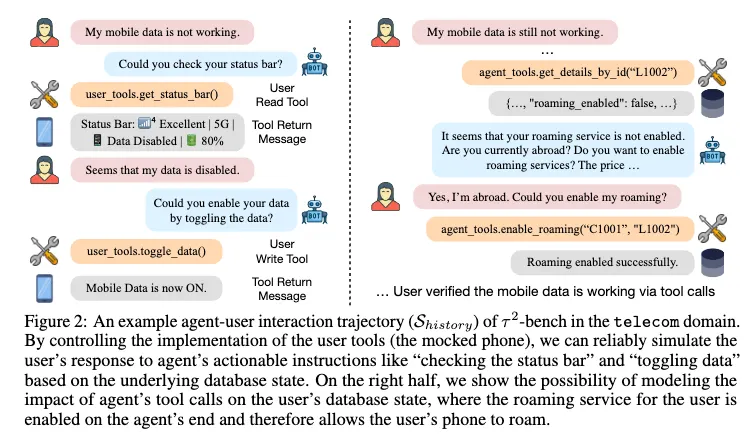
3.2 Domain and task creation
기존의 tau-bench와 유사.
- Creating agent’s database schema and tools
- domain의 핵심 비즈니스 로직을 설명하는 PRD 작성
- PRD: 고객 CRM을 정의하고 이를 관리하기 위한 함수들을 제작
- Creating user’s database schema and tools
- 사용자의 핸드폰을 mock으로 구현
- 상태 정보, 다양한 기능들 포함.
- Programmatic task creation
- combination으로 다양하고 검증 가능한 태스크 생성
- service_issue, mobile_data_issue, mms_issue에 대해 15개의 atomic subtask 그룹 개발
- 그중 프로그래밍 방식으로 조합하여 2,285개의 태스크를 만들었고 그중 114개를 샘플링하여 user intent와 subtask 개수에 걸쳐 균형 잡힌 분포 구성
- task creation example
- {${f^{init}_{t,k}}$}: 문제의 원인 ex) 사용자의 휴대폰 상태에 비행기 모드가 켜진 상황을 만듦.
- {$f^{sol}_{t,k}$}: 도구로 해결 ex) toggle_airplane_mode()로 비행기 모드를 끔.
- {$f^{assert}_{t,k}$}: 정상 상태 검증 ex) assert_service_status(”connected”)로 모바일 데이터가 되나 확인Atomic subtask (개수 명시 안 됨)
- 비행기 모드 켜져서 데이터 안 됨
- 데이터 설정 문제
- SIM 카드 오류 …
- 비행기 모드 켜져서 데이터 안 됨
- 근데 그걸 다 쓰지 않고 service_issue, mobile_data_issue, mms_issue가 골고루 나오게 114개를 뽑음. 여러 개의 Intent가 섞이지 않은 것들만 사용.
- (각 그룹에서 선택 가능한 subtask 수 + 1) 를 모두 곱했더니 2285개 도출
- 태스크와 해결책을 바탕으로 LLM에게 프롬프트를 입력하여 도메인별 에이전트 정책 생성
- 문제 해결 상황에서는 agent가 사용자 문제를 진단하고 해결하는 데 도움이 되도록 사용자 의도별로 문제 해결 절차를 제공함.
- Manual refinement
- 관련 모든 자료들 정제
- 각 태스크에 persona 지정 가능.
- None: 아무 페르소나 없음 (기본값)
- Easy: 도메인에 익숙한 사용자
- Hard: 기술 지식이 낮은 사용자
3.3 Task evaluation
태스크 성공 여부를 판단하는 방식
- DB check
- DB 상태를 기준으로 평가
- Status assertions → Telecom에서는 이거만 사용
- 최종 world state S_world에 대해 정의된 조건 확인 (특정 tool이 true인지)
- Natural language assertions
- 대화 이력 S_history에 대해 조건 충족 여부 평가 (특정 문장이 포함되어 있는가)
- Communication info check
- agent가 특정 정보를 유저에게 전달했는지 평가 ?
- Action matching
- 미리 정의된 solution action들이 실제 실행되었는지 평가 (특정 tool을 불렀는가 → every solution tools를 불렀는가)
4 Experiments
4.1 Agent settings
- 평가 대상 LLM: gpt-4.1-mini, gpt-4.1, o4-mini, claude-3.5-sonnet
- User simulator: gpt-4.1
- LLM 실행 횟수: 각 태스크마다 4번 실행
- temperature: 0
- prompt 구성: agent/user 모두 공통 가이드라인 + task/domain-specific 정책 포함
4.2 Results
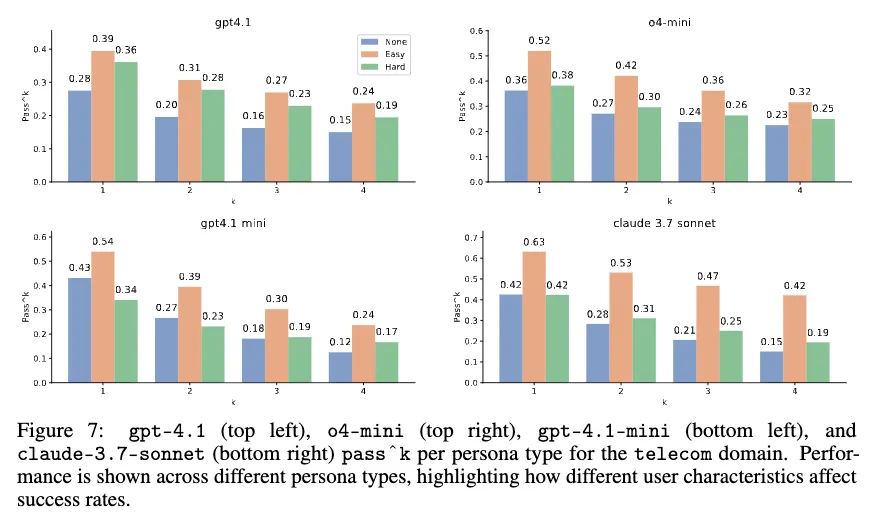
$Pass^k$ scores

기존 tau1에 있던 retail, airline 도메인보다 telecom 도메인이 훨씬 어려운 task라는 것을 알 수 있음.
Ablation analysis
Agent의 성능에 영향을 주는 두 요인이 있다.
- 커뮤니케이션 능력: 사용자와 효과적으로 상호작용을 하며 문제 해결
- 도메인 정책 적용 능력: policy를 읽고 적절한 도구를 호출하는 능력
이 두 가지 요인에 대해 평가하기 위해서 추가 실험을 진행
- Default: Agent와 User가 함께 협업. User simulator가 실제로 작동함 → 전체 능력 평가
- No-User: User simulator 제거 → Agent가 user 도구까지 다 직접 호출함. 단, 문제 요약이 주어짐 → Reasoning 능력만 평가
- Oracle Plan: Ground-truth plan 제공. Agent는 이 plan을 사용자와 협력해서 수행만 하면 됨 → 커뮤니케이션 능력만 평가
Impact of policy document on performance
Impact of number of actions and sub-tasks

Impact of issue types

Impact of user persona
5 Conclusion
성과
- 기존 tau-bench를 확장하여 dual-control 환경 도입
- LLM들이 추론은 잘하지만 coordinaion과 communication이 추가되면 성능이 급감함을 확인 가능
User Simulator 한계
- 사용자 시뮬레이터 일반화 가능성은 열려있지만 아직 확장을 해야함.
domain 확장 자동화의 어려움
- 도메인을 확장하기 위해서는 여전히 사람의 개입이 필수적임.
전문가와 초보자의 격차 미반영
- 고객지원 상황에서 나타나는 전문자와 초보자 간의 이해 차이를 명시적으로 반영하지 못함.
- 이러한 gap을 다루는 부분도 추가되어야함.