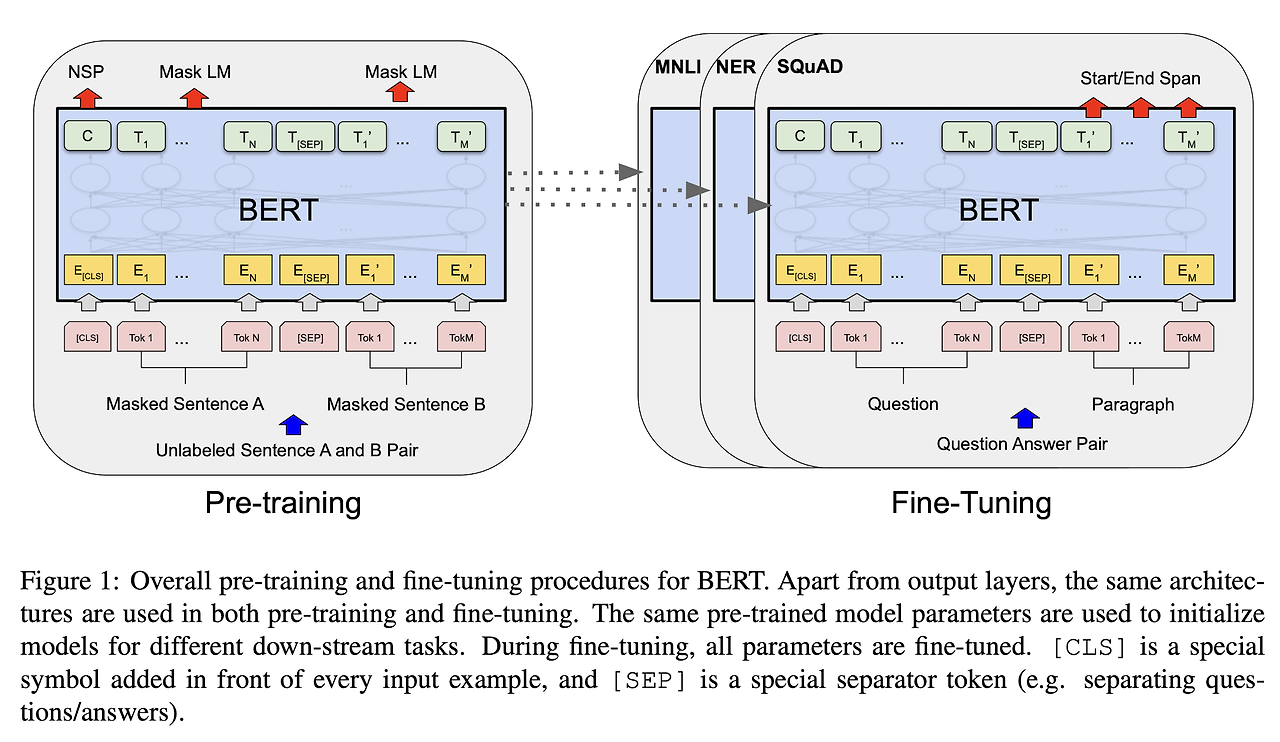
Abstractpre-trained neural language model은 많은 NLP의 성능의 향상을 가져왔다. 해당 논문에서는 두 개의 새로운 기술을 이용하여 BERT와 RoBERTa 모델을 향상시킨 새로운 model architecture DeBERTa (Decoding-enhanced BERT with disentangled attention)를 제공한다. 첫번째로 disentangled attention mechanism이 있다. 이는 Content vector, Position vector 벡터로 나눠서 단어를 표현하고 단어들 사이의 attention weight을 단어의 내용과 상대적인 위치에 따라 각각 disentanlged matrices를 사용해 계산된다. Content vector는..